The issue here, is, I have hundreds of files and I’d like to add more without having to manually embed an audio file link that can get broken over time. I want to dump my audio in a folder and have a program arrange them into a grid so that I can listen to them just by clicking on a button. This interactive platform is for me (and I’d like it to be online so other researchers can use it too!)
I wanted to give you all an update on my progress on this project. I took @mjcarroll’s advice and tried to get Google Sheets to serve the purposes of this endeavor.
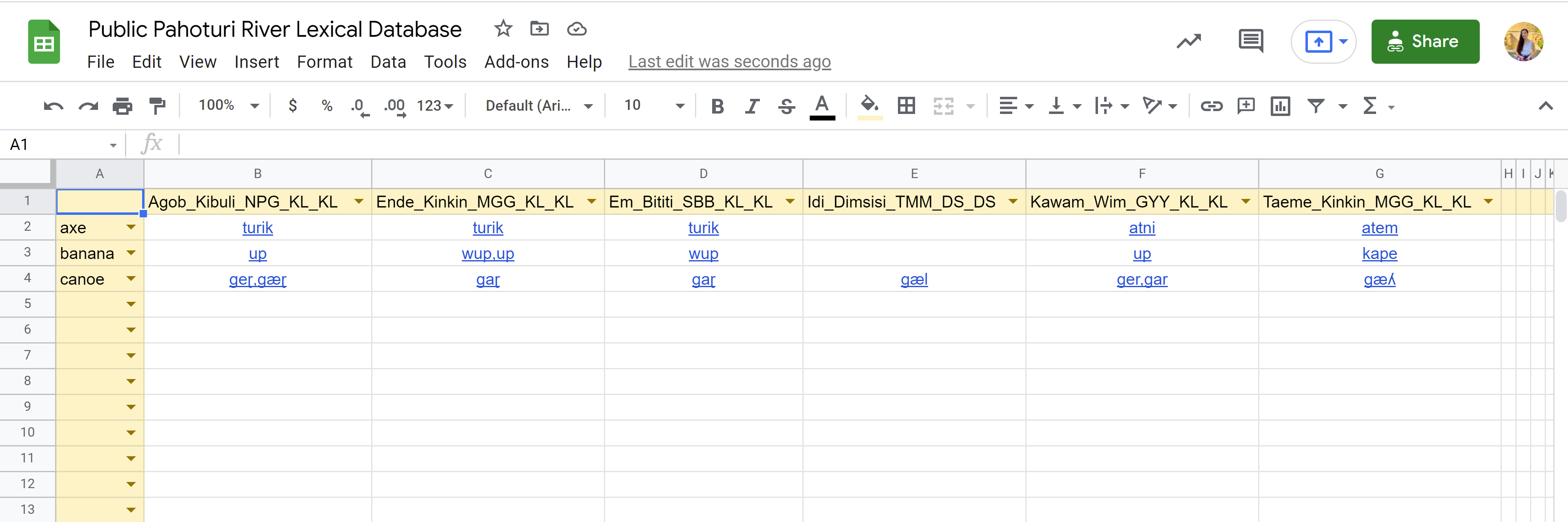
I created a sheet that includes a dynamic table that allows you to select a language/transcriber (organized by column) and a gloss (organized by row) and the spreadsheet will automatically fill in the table with a transcription of that gloss for that language by that transcriber AND a link to the audio file in my google drive.
I also found a way to automatically extract a list of URLs that correspond to each file in a Google drive folder so that I didn’t have to manually link each word to the audio file. by copying and pasting the link. (Very helpful, since there are more than 2000 audio files).
I’m still messing around with the formatting and functionality (with help from @rchon) and the end goal is to embed the editable spreadsheet into a Wordpress type website so that researchers can view the comparative data without seeing all the backend google sheets mess. I’ll also be able to include instructions and tips.
Thanks so much for sharing this, really interesting, and congrats on your progress.
I’m not a historical linguist myself so I don’t do much in the way of comparative tables like these, so I was wondering if I could ask you a data question when you’re working with this kind of data. If I understand correctly, you’ve got for instance in the third row six forms which correspond to canoe. So my question is, how do you track cases where one of the languages has undergone semantic shift? Like, I could imagine canoe coming to mean something else — raft or rowboat or rocket ship or whatever.
Is that sort of information stored in some other context, or do you find that working with a cognate-level gloss doesn’t really turn out to be a problem, even if it’s… er… glossing over some subtleties?
Great question. For historical/comparative work, it can be useful to have the data organized by cognate sets, that is sets of words that all have a common origin and may or may not refer to identical semantic categories (this would be your canoe-canoe-raft set) and to have the data organized with current synchronic glosses to look at semantic drift. Cognates though are key for the comparative method and the semantics have to be close enough that you can argue that they have a common origin to use it for reconstruction work.
In the spreadsheet, each transcription-gloss pairing has a column with gloss notes (to discuss semantic differences or shifts) and transcription notes (to discuss different analyses in transcription).
How fantastic! Great to see you’ve managed to pull-off the dynamic display and linking to your sound files!
This is exactly what I wanted for Yamfinder when we did it the first time and I wish I had of started here (although google docs wasn’t as nearly developed in 2012). Can’t wait to follow this as it develops.
If you send the current data my way ( robert_forkel at eva.mpg.de ) I could set up a skeleton on github for the conversion. From there, setting up a clld app might be an option. But maybe - someday - there’d be a CLDF plugin for wordpress, which would make deployment of web sites based on CLDF data a lot simpler. (I’d leave that to someone else, though, being happy to have escaped Wordpress myself )
 or whatever.
or whatever.