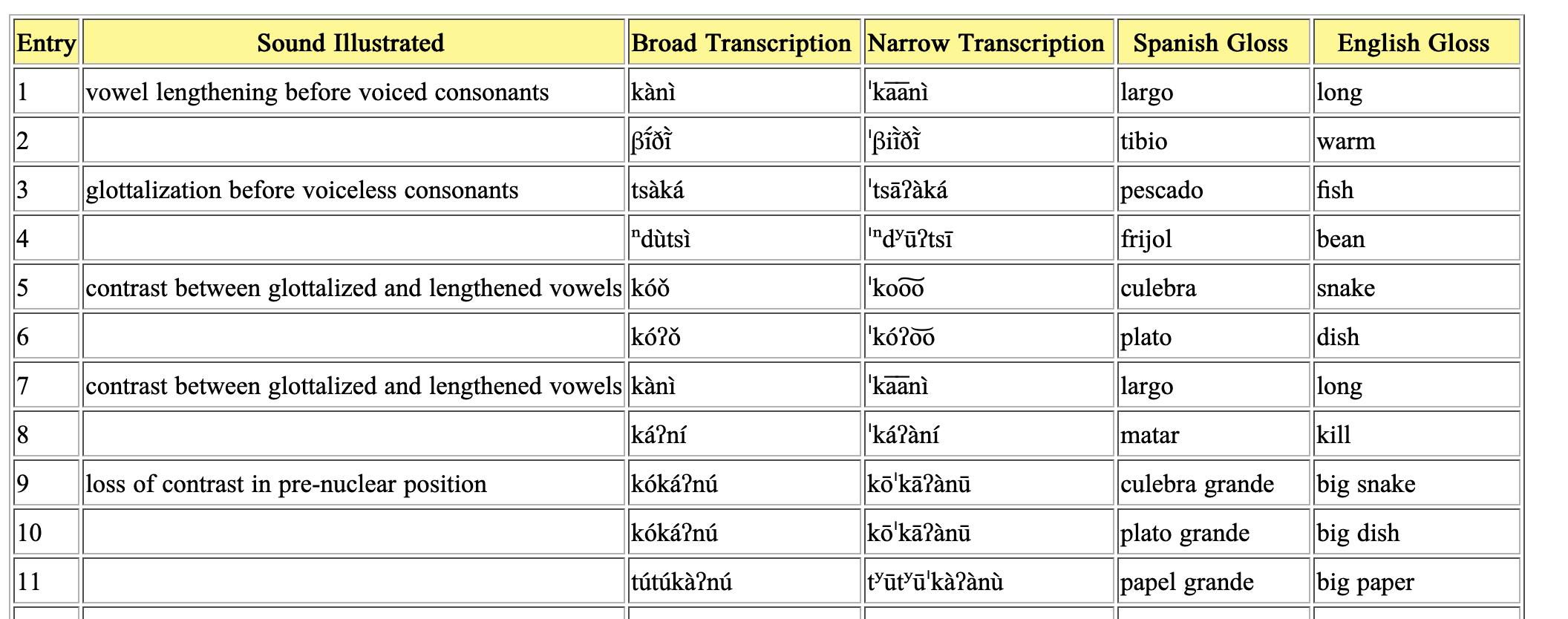
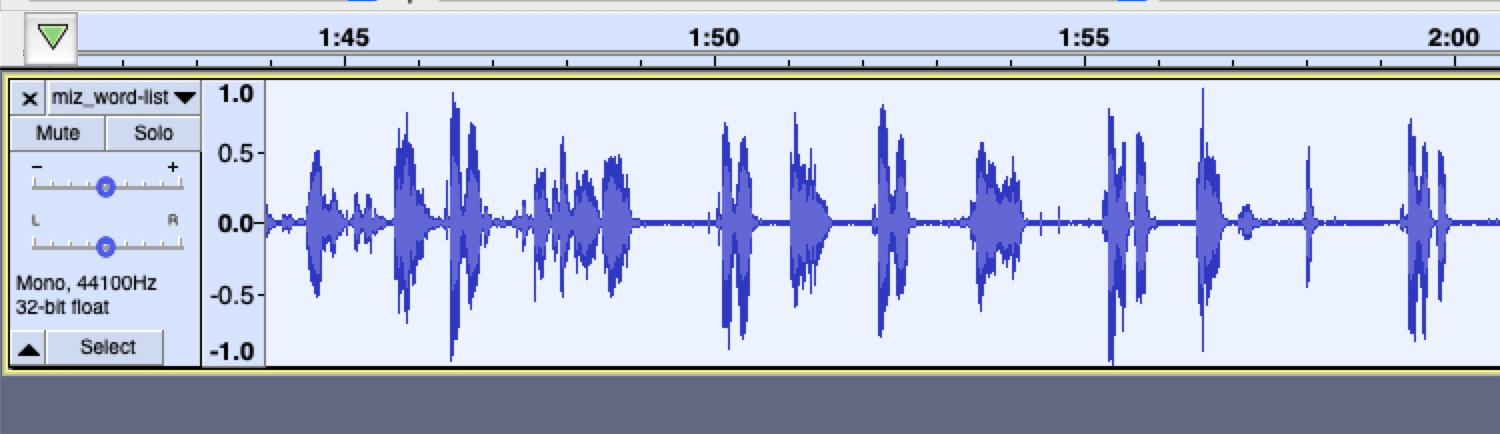
But what’s missing is timestamps. There are 73 words, each with a prompt followed by the enunciation of the word. It’s not great audio quality, but the waveform seems clear enough:
I’d like to add the timestamps for each word, but doing that by hand sounds like a grand old pain in ye butt. What would be easier would be to get some “guesses” for which bits of the audio are words, and then line up the existing transcriptions with those guesses. Surely it will require post-editing, but it would still be easier than starting from scratch, selecting each word in the waveform.
So I have been trying (unsuccessfully) to use the Analyze > Label sounds… function in Audacity. I have also heard that Praat can do this kind of thing. I’m a bit of a Praat know-nothing, I will admit.
ELAN has a silence recogniser and will segment out all the silence - it might need a WAV rather than mp3, but I’ve definitely used this before for the first step of annotating wordlists! (a while ago, hence the vagueness on details!)
You need to open the audio file using “Read from file…” instead of “Open long sound file…” in order to use this feature.
Select the audio file in the objects window, choose the “Annotate” button, and then “To TextGrid (silences)”. You can mess around with the settings to get the best results.
This was the method I used in a previous elicitation workflow. If you create a very consistent recording then it is possible to segment it more or less 100% automatically.
Edit:
And then after you have created the time segments you can write a script to combine the text data and time data, which saves you from having to manually re-type or copy-and-paste the text data.
Thanks @rgriscom and @laureng. I will try both of these when I am back home with my laptop. I’m on vacation! Which means that I can only nerd on my phone OH THE HUMANITY.
Interesting that you mention voice activity detection, Richard. It seems that it is doable with the Web Audio API, which opens the possibility of web apps being able to do this. I have found a few resources: