Good grief, this turned into a journal article. I’m just going to put out what I’ve got so far so I can move on with my life! Part II, about the app design, may happen… eventually…
So I got caught up in a Twitter thread (as one does) discussing the dialect of a narrator in the overdub of an online video. Here’s how it begins:
Here’s the source video the commentary refers to:
video

As it happens, the fact that there’s video is sort of besides the point, in this case — it’s really a podcast with (beautiful!) stock footage added after the fact; there is no video of people speaking. So let’s just concentrate on the audio. I extracted the relevant clip, here’s a playable version:
Here’s more of the unrolled thread from the original Tweetiste rgoatcabin:
Can anyone tell what type of English accent the speaker starting at 56:07 has? Quite an unusual one to my ears, especially for a documentary
He has t-glottalization and th-fronting and also monophthongizes, but what really throws me for a loop is his pronunciation of “asked” as /ɔ:kt/ with metathesis of -sk-, subsequent simplification of -skd- to -kd- and final devoicing, along with a very broad vowel. Actually, his final devoicing doesn’t seem regular, so it’s probably just progressive devoicing after -k(s)-
Right, the problem at hand is dialect identification.
In this post, I am going to (1) think out loud about what data are necessary for “digitally documenting” a proposal for a dialect identification, (2) sketch out some ideas for a user interface for collecting such data might look like.
 What dialect is that?
What dialect is that?
So, back to the Twitterers:
Later in the thread, rgoatcabin indicates that they have identified the dialect:
I’ve tracked down the speaker and he seems to be from East Anglia. That “awkt” is really something, though. It seems too non-standard to be idiolectal, so it must be a particular local feature
Still later in the thread, another theory is advanced that the speaker speaks Multicultural London English, or MLE:
It’s MLE, a strong West African flavour of it. Most likely someone second- or third-generation from a family of Nigerian or Ghanaian immigrants in London. I might be wrong but the way he says “to my plate” sounds a lot like a West African influence.
(Also, hey, @samo shows up! ![]() )
)
 There’s an app for that, but we have to design it
There’s an app for that, but we have to design it
So we have a raw recording, and some theories. What now?
It seems to me that essentially we want to get to this data structure, conceptually speaking at least:
| Dialect A | Dialect B | Dialect C | |
|---|---|---|---|
| Feature X | |||
| Feature Y | |||
| Feature Z |
I don’t know if there’s a real name for such a data structure, but let’s call it a Feature/Dialect matrix. (Obviously three features isn’t enough to identify a dialect, but we want a table of this shape.)
There are certainly methodological questions about how you should choose features and dialects for comparison in the first place. Hey, I’m just a data guy! I hope some sociophoneticians in the room set me straight about all this!
However the feature/dialect matrix is defined, it’s a reasonable basis for our second question: what should an application for collecting that matrix look like? The input is a recording, we’ll define the output as a feature/dialect matrix, then what user interface would help us get from the input to the output? How would we like to go about annotating and classifying phonetic features? The answer to this question can take into account things like ergonomics, ease of use, responsiveness, and even aesthetic preferences.
Dude, just use ELAN
Well, okay but…
Yes, we will probably want to align the audio to a transcription. Hey, it’s English, easy peasy lemon squeezy. Plus it’s a very short clip. We documentarians do have a well-developed class of applications for transcribing time-alignment information. The 500-pound gorilla of this category is ELAN, of course. But do we really need to wrestle with tiers and “linguistic types” and all nuttiness that for a 17-second clip? I think not. I used good-old Audacity to grab some timestamps:
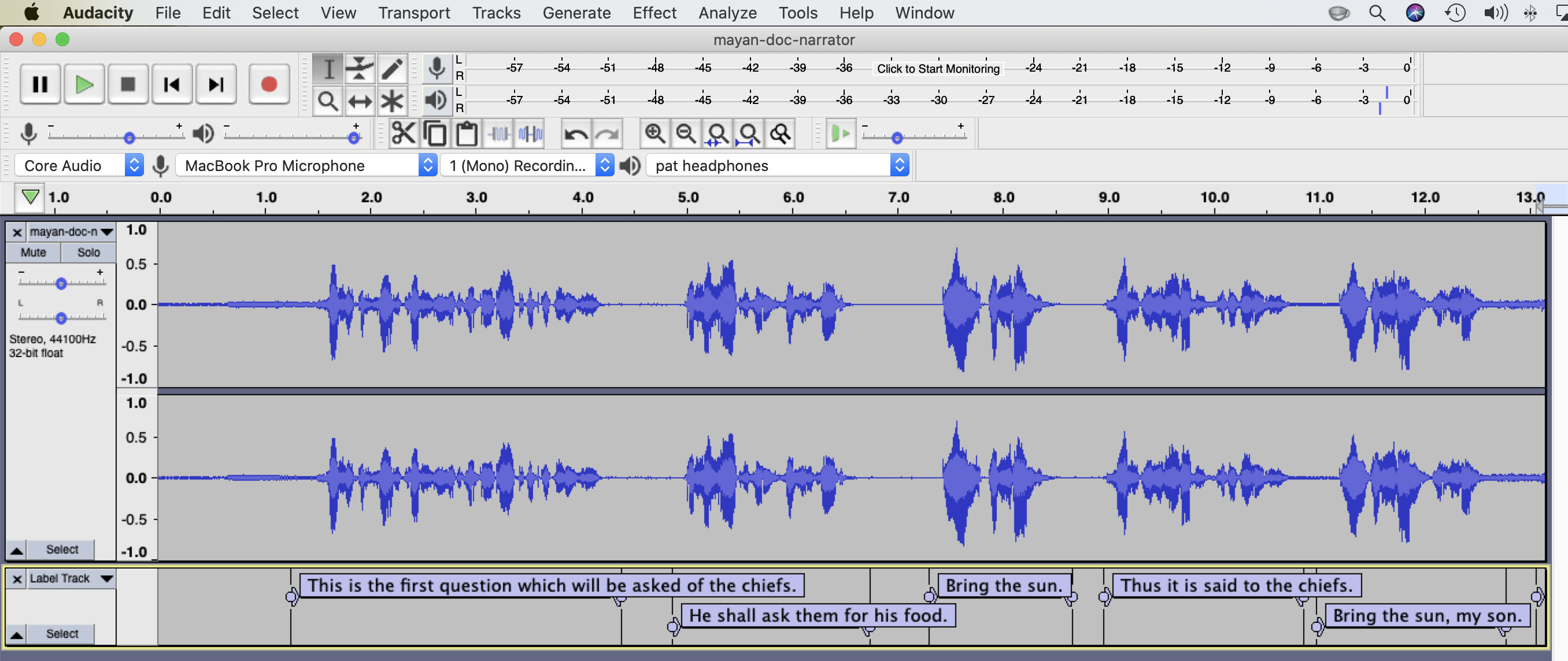
You know…
…we could also design an application for capturing time alignment via a web interface. Wave form selection, transcription, etc. Totally doable. But that’s a separate problem from the one we’ve stated. If I've learned anything about software development from trying to do it, it’s this: NEVER CHANGE THE SCOPE OF WHAT YOU'RE TRYING TO DO UNTIL YOU FINISH THE FIRST THING. Otherwise it’s a slippery slope of feature creep and you finish nothing.
If we export those transcriptions (Audacity calls them “labels”), we get a tab-delimited text-file, like this:
1.250493 4.387696 This is the first question which will be asked of the chiefs.
4.870343 6.746083 He shall ask them for his food.
7.305514 8.665700 Bring the sun.
8.961870 10.859548 Thus it is said to the chiefs.
10.980210 12.779165 Bring the sun, my son.
13.064366 15.653106 Bear it on the palm of your hand to my plate.
Let’s put some labels on the columns. Here it is as an HTML table.
(I rounded the timestamps, since Audacity’s are way too “accurate”. Whatevs, we’re not measuring voice onset time!)
| start | stop | transcription |
|---|---|---|
| 1.25 | 4.38 | This is the first question which will be asked of the chiefs. |
| 4.87 | 6.74 | He shall ask them for his food. |
| 7.30 | 8.66 | Bring the sun. |
| 8.96 | 10.85 | Thus it is said to the chiefs. |
| 10.98 | 12.77 | Bring the sun, my son. |
| 13.06 | 15.65 | Bear it on the palm of your hand to my plate. |
Here it is in God’s own data format, JSON
[
{
"start": 1.25,
"stop": 4.38,
"transcription": "This is the first question which will be asked of the chiefs."
},
{
"start": 4.87,
"stop": 6.74,
"transcription": "He shall ask them for his food."
},
{
"start": 7.3,
"stop": 8.66,
"transcription": "Bring the sun."
},
{
"start": 8.96,
"stop": 10.85,
"transcription": "Thus it is said to the chiefs."
},
{
"start": 10.98,
"stop": 12.77,
"transcription": "Bring the sun, my son."
},
{
"start": 13.06,
"stop": 15.65,
"transcription": "Bear it on the palm of your hand to my plate."
}
]
Maybe not as pretty to look at as an HTML table, but much easier to process in a computer program. Same information, in any case.
So far so good.
Was ist thus vəs?
Let’s do a thought experiment. Suppose I say to you:
The pronunciation of thus at
0:09is something like [vəs].
Stop right there! What does that MEEEEEAN

Well, let’s think about all the “bits of data” that are actually in play in such a statement. There are actually several!
- The starting timestamp
0:09 - The phonetic transcription [vəs]
- The orthographic transcription «thus»
- An implied comparison between [ðəs] and [vəs]
But what are we actually trying to document, here? Is it:
- The fact that the sound recorded somewhere around
0:09does in fact capture a voiced labiodental fricative [v] - The fact that the recording contains an utterance of the word thus, and that word is pronounced by this speaker, in this instance, as beginning with a voiced labiodental fricative [v]
After all, 17 seconds tells us next to nothing about this speaker. Do they ever use other dialects? Is their pronunciation characteristic of a speech community, or idiolectal? Who else is in their community? Do they ever use [ð] (or [θ] for that matter)? Etc etc.
An application can’t “automate” sociolinguistics! What it can do is to help us to annotate our data in such a way that we can make a responsible characterization of what kind of (testable!) assertions we are making about that data.
- You think this speaker always has [v] where the “standard” dialect has [ð]? Cool.
- You think this speaker uses [v] and [ð] in some kind of distribution in certain words? Different hypothesis, also cool.
Our application is just supposed to help us demonstrate our case, whatever our hypothesis may be.
One still might counter that this is still just a matter of collecting transcriptions and timestamps: all the [v]s, say. “Dude, use ELAN. Or fine, Audacity. It’s just timestamps!!” Yes, we’re going to need to do that. But I would like to suggest that there is an opportunity to think of the workflow that we want to carry out as a design problem, not just “doing time-alignment”.
Suggested phonetic features
Here are the features mentioned in the original tweet (quite a few!):
- t-glottalization
- th-fronting
 our guy
our guy - monophthongization
- “asked” as /ɔ:kt/ with metathesis of -sk-
- simplification of -skd- to -kd-
- final devoicing
- very broad vowels
I’ll tell you straight up that I’m not familiar with the usage of all of these terms in English dialectology — not my bag — rgoatcabin is clearly a sociolinguist of English. But we can probably identify some of them. And any of them could go into a feature/dialect matrix.
Your call is very important to us! Please hold for Part II!
(Also, aside from these user interface questions, isn’t it awesome to hear an (uh, what’s the right word?) “unusual” dialect in a context like this? I love it.)