Hello DocLing,
This is the first post of the thread detailing the adventure @pathall and I are embarking on to use coding to do better linguistics. I, Sarah, as you might know from my other thread about Abkhaz and converbs, asked Dr. Pat to apply his awesome dissertation-fueled knowledge to help me learn to do some coding so that I can do more things with my converb data. He has (luckily) agreed to help – as it’s his mission to bring coding to the field linguists. And maybe we’ll get some more imput from our lovely forum along the way. ![]()
First I’ll provide a bit of background and then give a quick summary of the main points of our first virtual meet up (along with my “homework” in case anyone out there wants to follow along!)
The Project:
Surveying converb constructions in Abkhaz (describe what’s happening from all the angles relevant to the cross-linguistic concept of “converb” – not easy, lots of angles)
The data:
Currently: Example sentences from written (academic) literature – mainly from Aristava 1960 (Abkhaz examples written with the Abkhaz orthography, based on Cyrillic, translated into Russian, no glossing) and Chirikba 2003 (romanized Abkhaz examples with glosses).
Future: more examples from academic texts, from general writtings in Abhkaz (books, internet writtings, whatever) and hopefully some examples gathered from spontaneous speech in the field.
(Some) Overall Goals:
Build someplace for my examples to live (corpus);
Have the software look for examples based on, essentially, a filter system (so I don’t have to go through every example by hand every time looking for X converbal suffix with SS reference indicating simultaneity)
Where to start:
As you can see, there’s a lot happening in the background (I left some things out but maybe Pat can articulate them later ^^;), a lot of ideas and, hopefully, a lot of data. But we have to start somewhere to be able to get to the point where we can build this magic, helpful program. This is what Pat and I discussed.
First, I need to develop a workflow that takes my “analog” examples and makes them program-readable. The examples I mentioned from Aristava 1960 and Chirikba 2003 are both in PDF format. But I need to turn them into a “text object”. The way I’m doing this right now for Aristava 1960 is, honestly, just transcribing examples from the PDF into an Excel sheet like this:
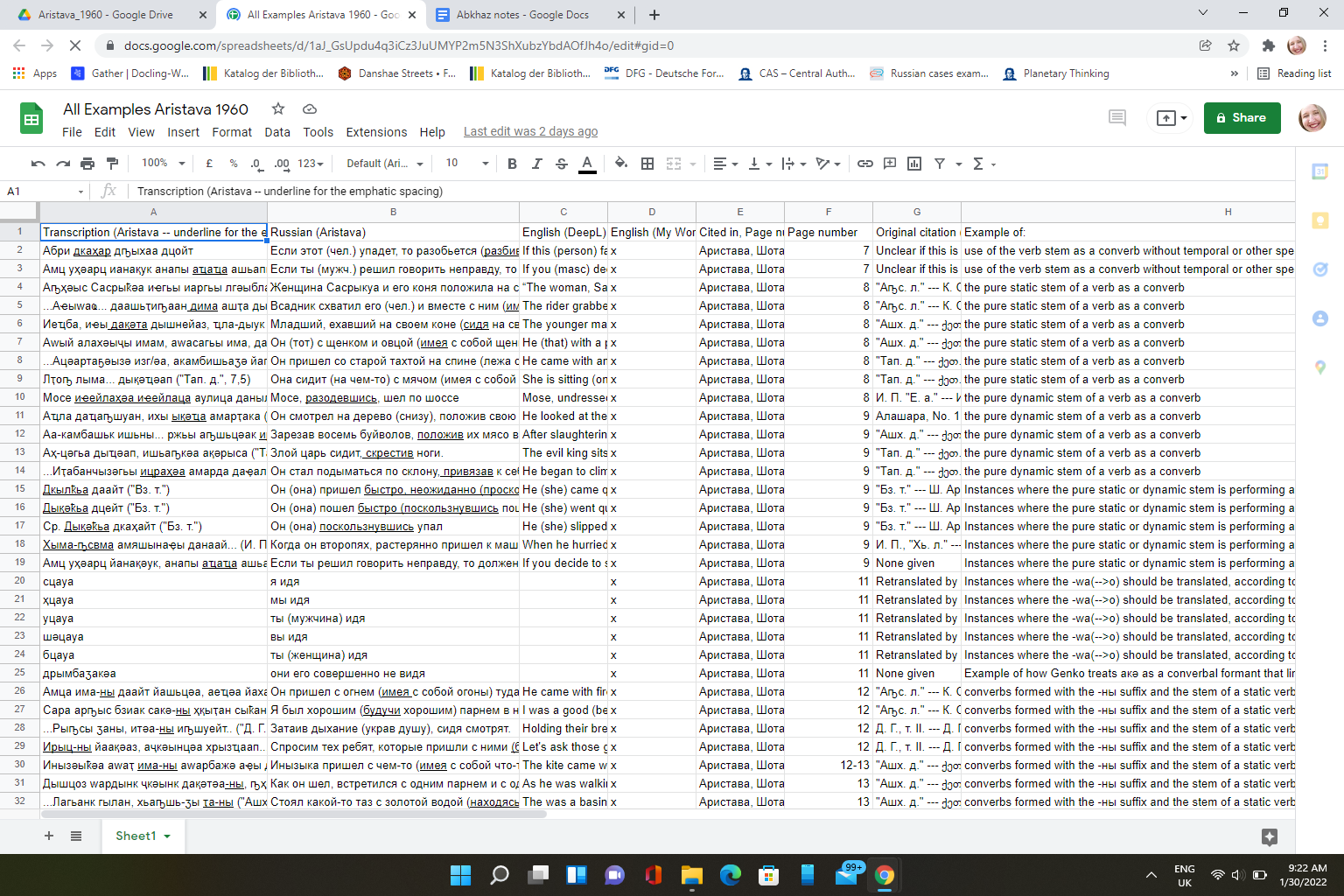
For Chirikba 2003, Pat already started with the PDF and then did *something to extract the examples from the PDF into a sort of “plain text.” It did ok, except some of the orthography got wonky and the glosses don’t match up nicely with the words/morpheme breaks.
*Not sure I can explain what yet
Basically, we have:
Input: PDF, Excel file with transcriptions in it
and I want
Output: a text object (JSON), which can be viewed (in a docling.js )
My Homework:
- Keep transcribing Aristava examples
(Got to do it somehow, and this is a useful drudge for me in several ways)
- Download https://code.visualstudio.com/
(Not immediately applicable for this homework but will be useful later)
-
Read the relevant part of Pat’s thesis (I didn’t post the link here since this is the as yet unpublished version)
-
*Edit Pat’s aforementioned slightly wonky text file so that a.) the first line is the sentence number and the last line is the translation, and b.) the transcription matches up with the gloss (because sometimes the place where the page breaks for the transcription is not the same place where the page breaks for the gloss).
- Will take a screenshot and put it in the next thread
Two other important ideas I took away from our meeting:
You are a documentation designer!
When the transcription drudge is a useful drudge, it’s an important part of this workflow and, therefore, is not a waste of time.