I want to make sure that this is not a solved problem before trying to tinker around in this area (or get some NLP people to tinker for us). I am about to go do fieldwork in which the language of elicitation will be English or Cameroonian Pidgin English, and the responses will be in a mixture of English, Cameroonian Pidgin English, and the target languages. Speakers will generally speak more than one target language. There might be code-switching within utterances, as in:
“ʒʉ́ na one, bə̀ʒʉ́ na many, sugye ant.” (plain = target, italic = Pidgin)
Similarly, I have a student who’s got hours of recordings in mixed northwestern Mandarin and Xibe (a Tungusic language), with some code switching within utterances.
If you want to auto-transcribe (using ASR) speech from an elicitation session, you need to mark off where speech is and isn’t happening, and you also need to ID particular speakers if you’re going to go on to do forced alignment on the data (as a phonetician, I definitely will). This process (diarization) is already tricky, but I imagine that it’s much harder when speakers are switching between languages. And of course for many purposes of diarization, you need to know the language being spoken in that interval (in my case, so you can select the right acoustic model for forced alignment, or use the correct data set to train an acoustic model for a particular language).
So:
Is there already a general solution, or general architecture, that solves the diarization issue? (For example, a script that spits out a list or array of diarization time points separated out by speaker, then language, which one could turn into a TextGrid or whatever else.)
How to deal with code switching within an utterance, which seems particularly hard?
Has any NLP work/linguistics work/joint work gestured at this as a problem (but not solved it)? I might need to do a little lit review…
Are there any considerations I’m missing in this discussion? (Would this be useful for other field situations beyond my own? Would there be problems for other field situations?)
Don’t have time for a full response atm but just want to pop in and note that diarization has received a fair amount of attention in NLP, including recently: Google Scholar. Will try to come back and say more later!
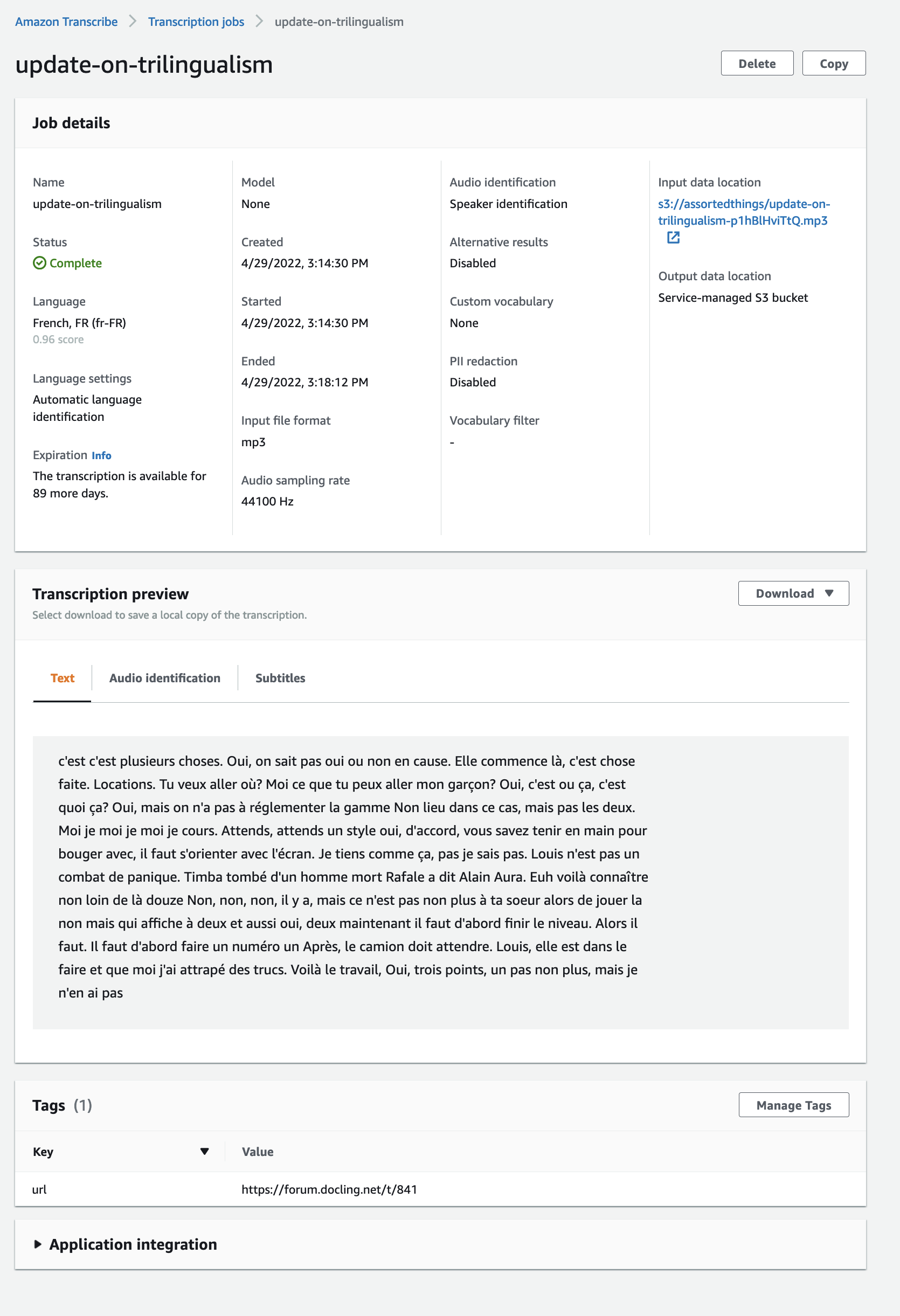
Well, I have some negative results to share, I guess!
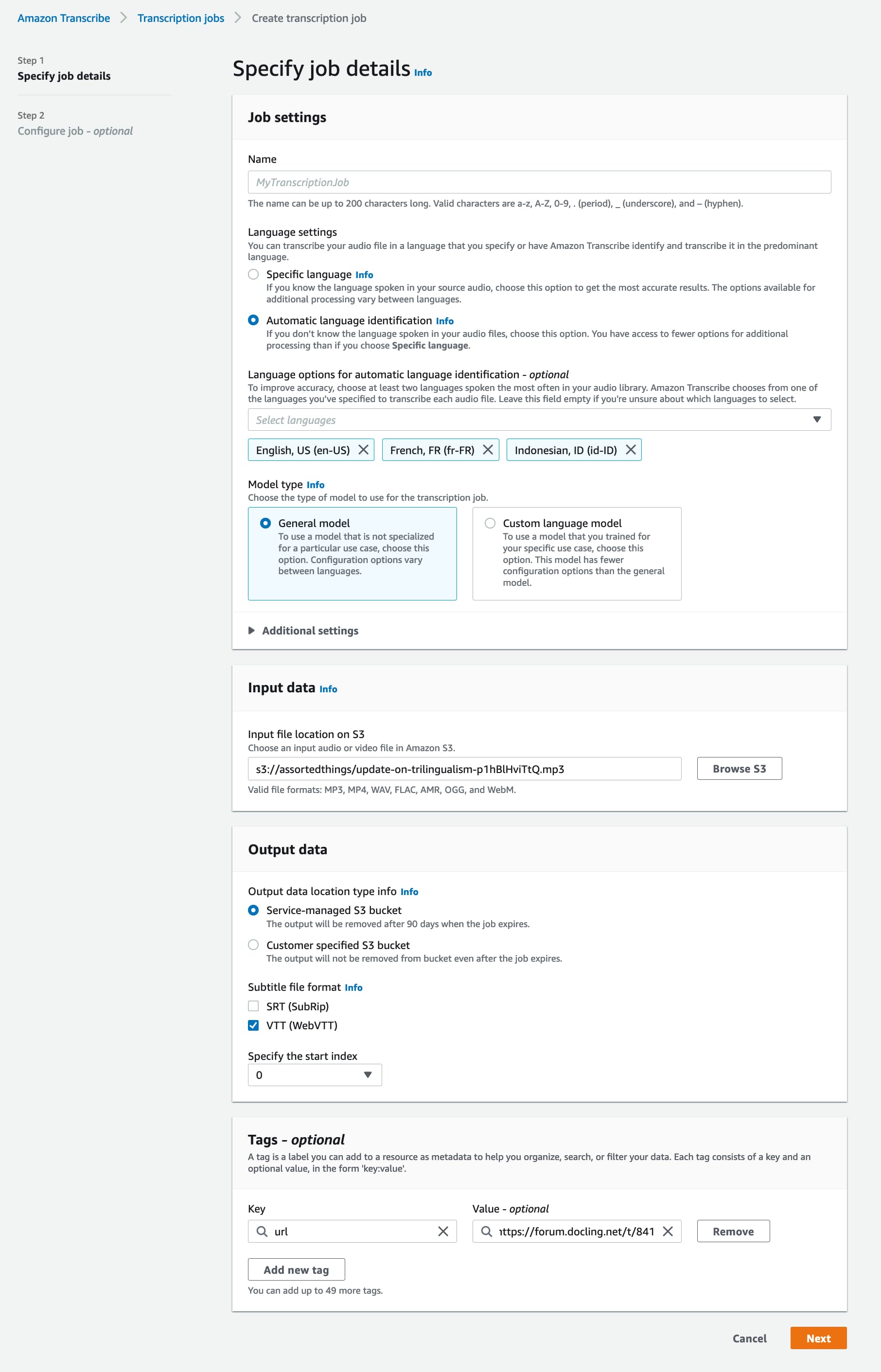
My only experience in this area is messing around with Amazon Transcribe — it does have some diarization features, but the results do not look good. There are plenty of issues around using an Amazon product, of course.
I either made a mistake or the quality was too low, but it looks like it’s not doing any language identification as far as I can tell (it assumed everything was French, despite my configuration saying that there was French, English, and Indonesian content).
And, it only seems to have identified two speakers, despite configuring it to expect five.
You might also be interested in @nikopartanen’s comment in the topic linked above:
(Replying in multiple posts because I’m limited as a new user to 2 links per post)
Hi @faytak — how timely! I have some answers (informed through a lot of trial and error):
Is there already a general solution, or general architecture, that solves the diarization issue? (For example, a script that spits out a list or array of diarization time points separated out by speaker, then language, which one could turn into a TextGrid or whatever else.)
Are there any considerations I’m missing in this discussion? (Would this be useful for other field situations beyond my own? Would there be problems for other field situations?)
One thing I note from having run timed experiments for correcting the voice activity detection/language identification output is that we found that the machine-assisted workflow for VAD+SLI offered no time savings over doing it manually — because code-switched speech is very hard to segment, and annotators found it more frustrating to correct bad output than to start from scratch. All our time savings came from ASR speeding up the transcription of parts identified as English…
pyannote on huggingface looks pretty excellent and I will have to look into it, thanks. any time savings compound pretty quickly during and after fieldwork so I’d be perfectly happy with good speaker detection/diarization that I need to add the language switches into manually. so much time during annotation is just spent scrolling.
 - codeswitching")