Hi Docling forum,
I’ve been working for a while on an annotation app I call Glam, which is finally approaching an alpha release. I’ve worked on with particular attention paid to its possible uses for language documentation, but it is intended as general for any kind of linguistic annotation. I’d like to hear your thoughts on what I have so far as I complete work on the foundations.
Introduction
As many of you here know firsthand, the apps we have for annotation today are held back by two problems: they are often tailored for certain domains, being annoying or impossible to use in other circumstances; and they have major usability issues which are rooted in outdated or poor engineering decisions. With Glam, I’m trying to tackle both problems: Glam has been designed to be universal in applicability across different domains of the field of linguistics, and it has been built with solid, modern engineering practices.
Universal Data Structures
How can the data structures be universal? The strategy is very simple—there are only four fundamental data structures: texts, tokens, spans, and relations. Texts are simply sequences of characters, and tokens are subsequences of texts. A span is a grouping of one or more tokens, and a relation is an edge between two spans. That’s all. You might be skeptical that this is really enough, but it’s been shown (e.g. by Jiang et al., 2020) that virtually all common linguistic annotation schemes are expressible using these basic elements.
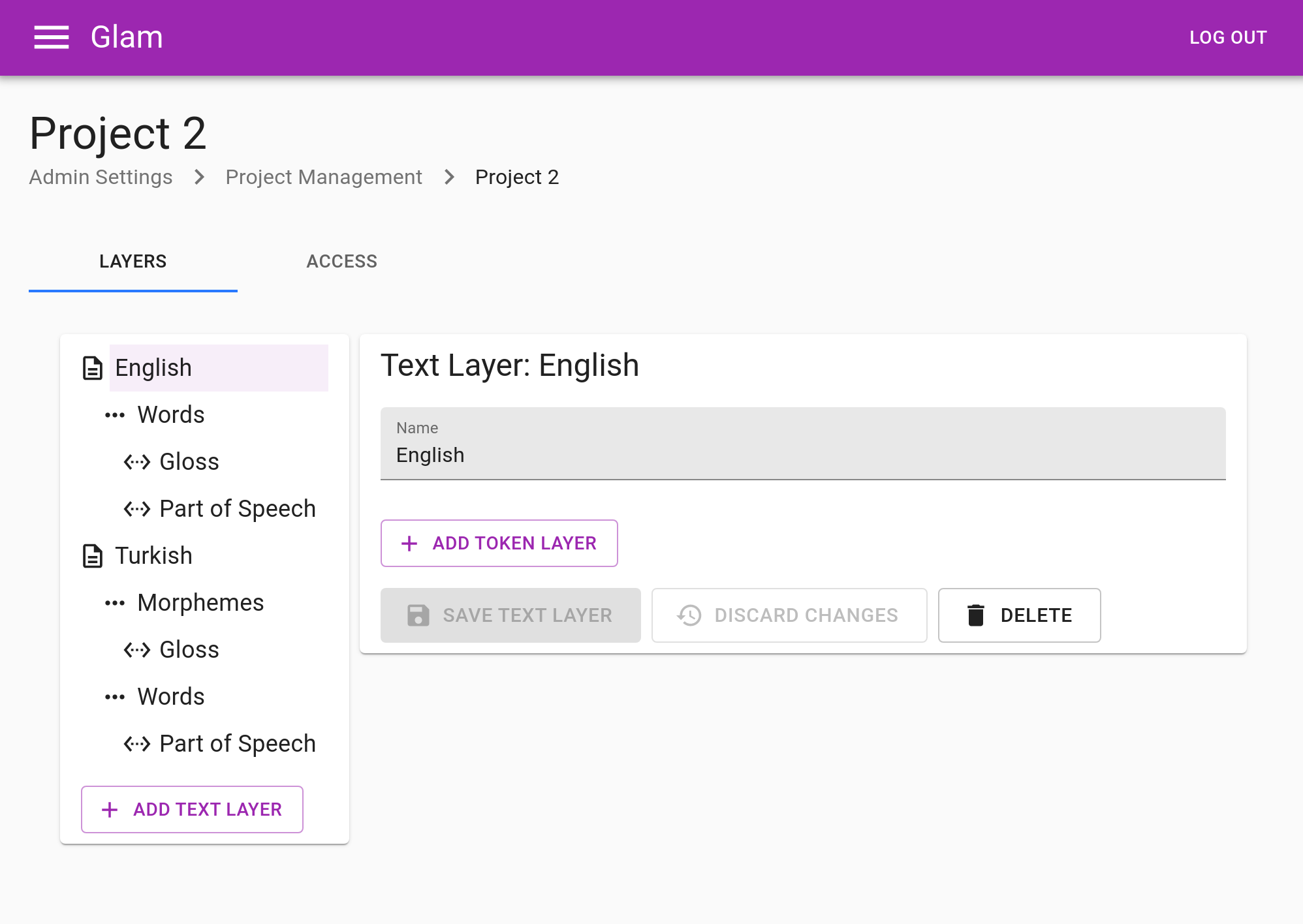
Every project in Glam, then, is configured using these basic elements. Consider for example how a project set up for parallel English–Turkish text might look: there are two text layers, the Turkish layer has two token layers (one for morphemes, the other for words), and all the token layers have span layers underneath. If you’ve used ELAN, this sort of configuration will be familiar to you: the four building blocks are used as your project requires them.
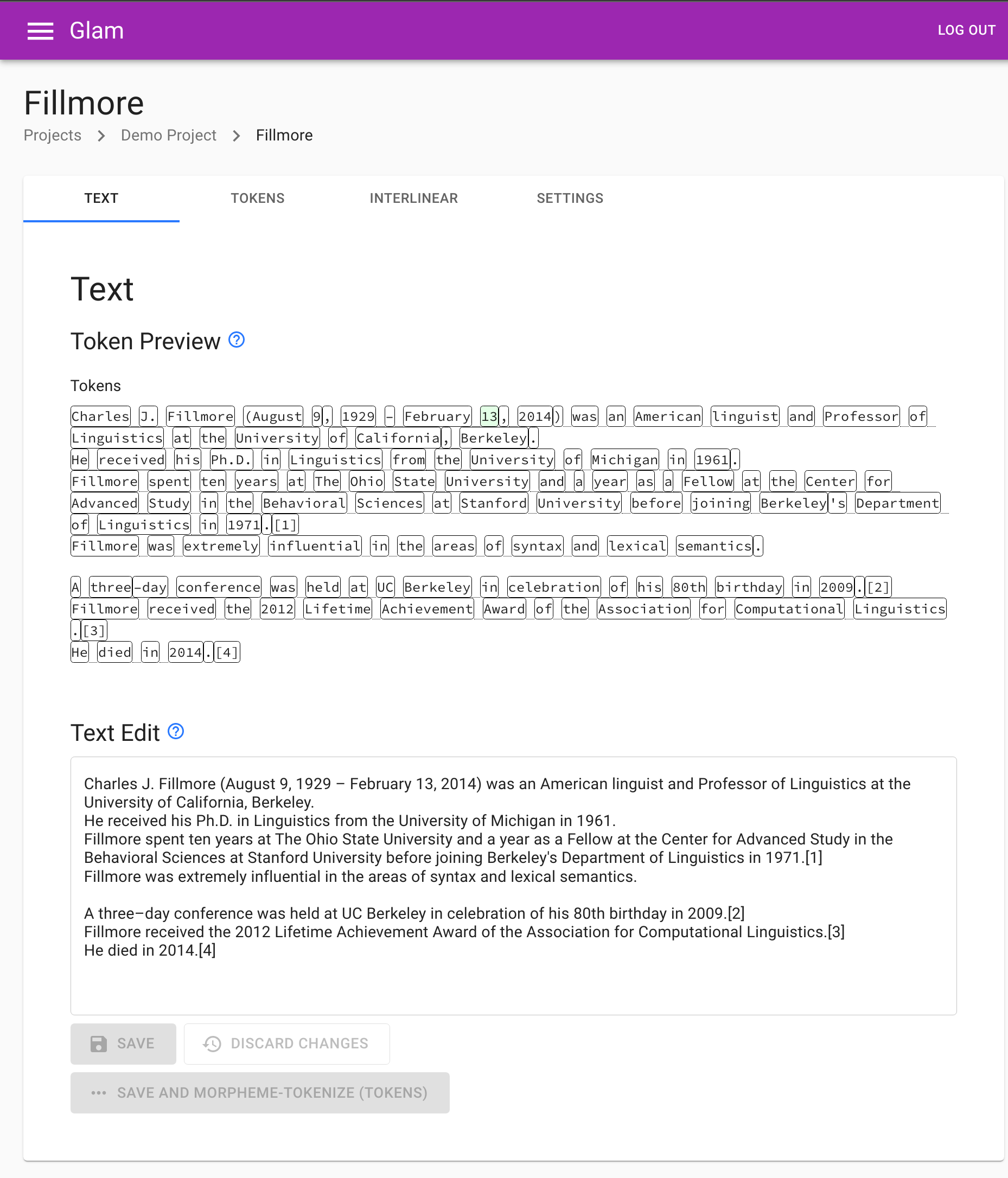
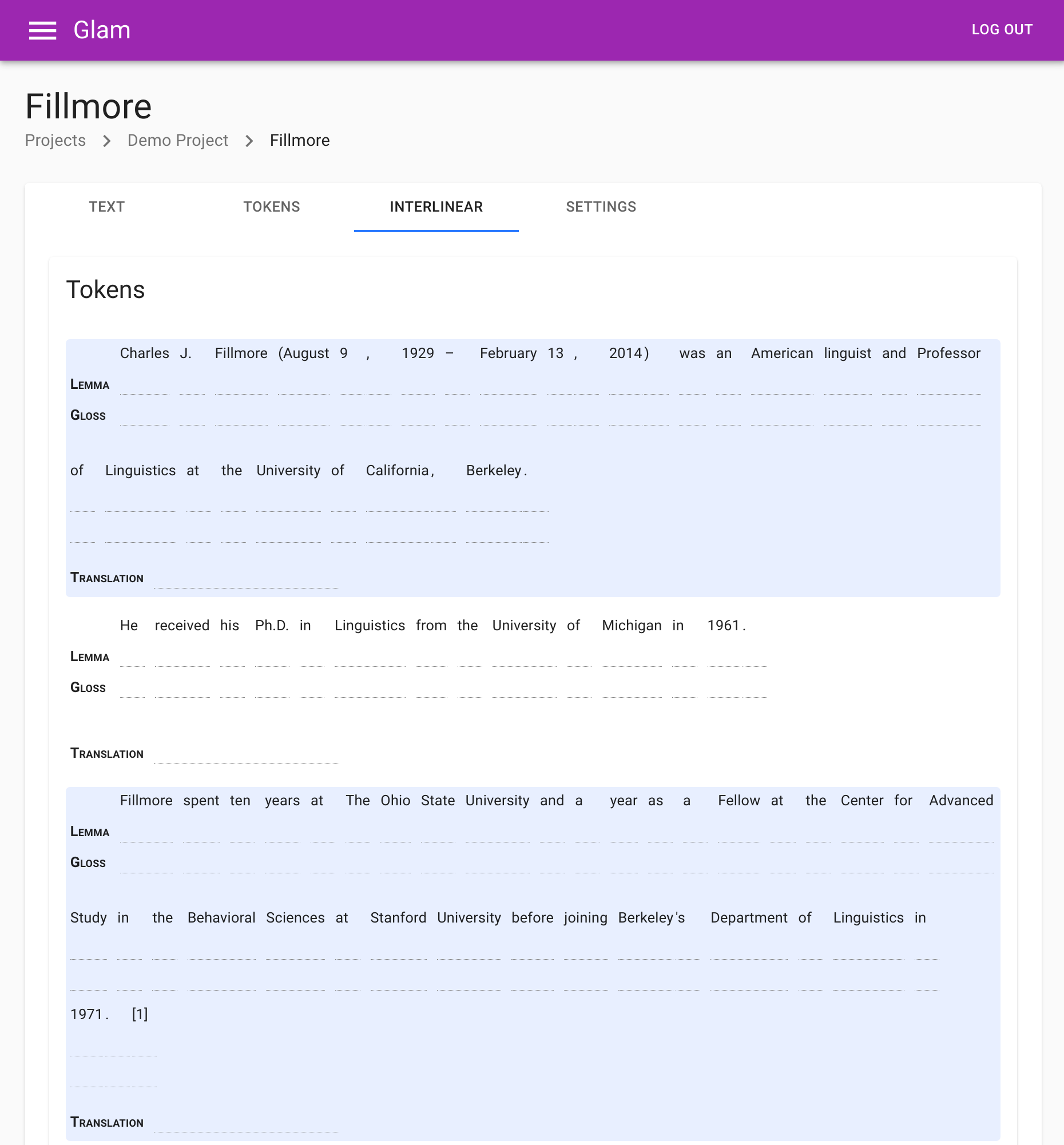
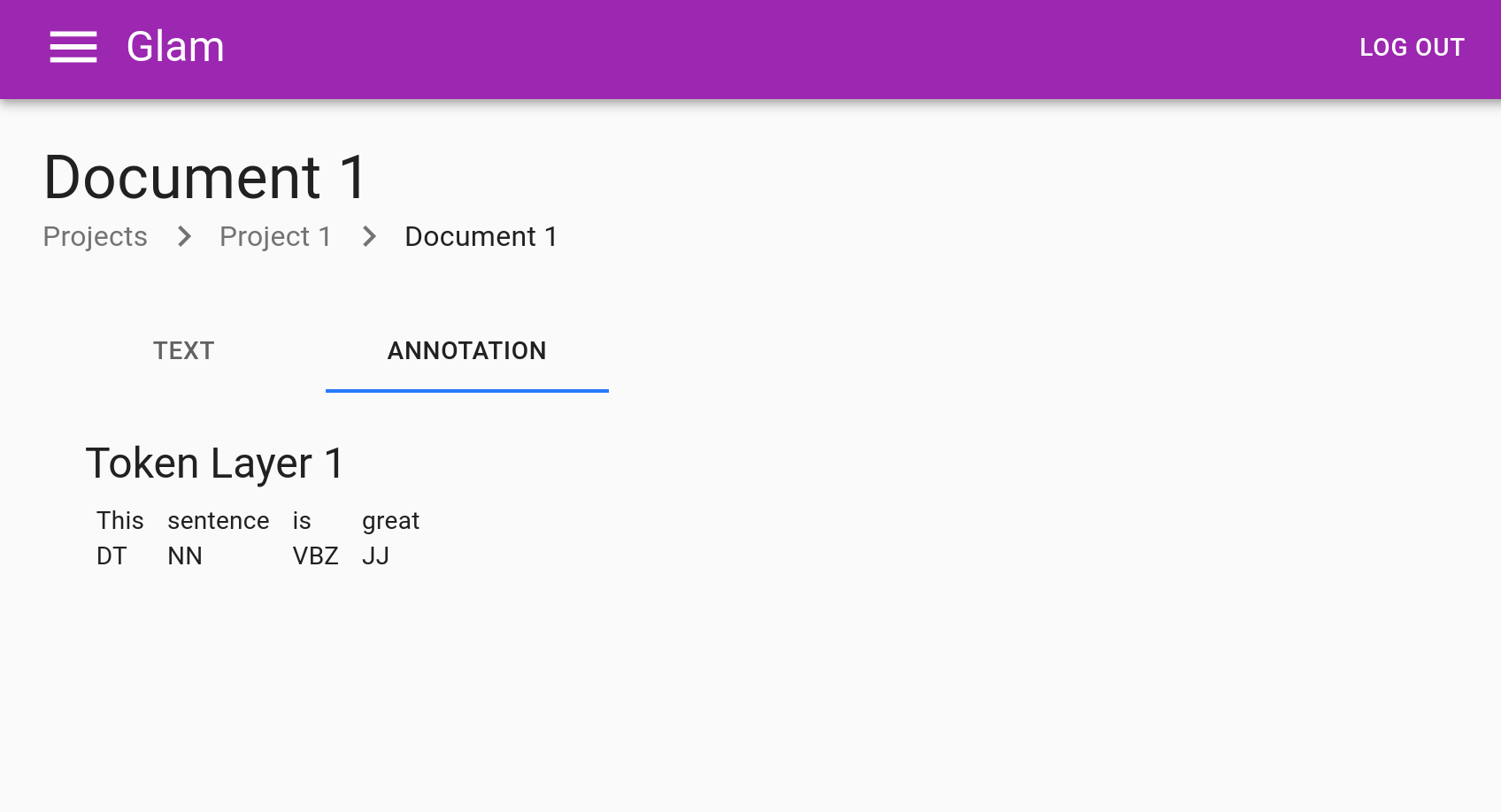
Documents will then have contents according to this configuration. Here’s a simple example, with just a single text layer, token layer, and span layer each:
Modern Engineering
I’ve made engineering decisions with an eye to (in order of decreasing importance) correctness, usability, universality, and efficiency in making Glam. Glam is implemented as a modern single page web application (this is the same class of apps that e.g. Twitter and your credit card website are in), and all the expected features exist: a full user system with project-level read/write permissions, an admin panel, automatic data synchronization, a clean and consistent UI, and more.
In addition to these benefits which are of fundamental concern, there are also a lot of nice-to-have features I was able to get along the way (disclaimer: some of these aren’t totally implemented yet, but I am confident they will be achievable with low effort ![]() ):
):
- Time travel and change logging: unlike a traditional app, Glam uses a database (Crux) which allows it to keep track of all the data-states the app has ever been in. That means you can view the state of your documents as they were on any given point in time, and that you can see a log of all changes that have been made.
- Real-time collaboration: users can work on whatever they like, even the same document if they wish, without having to worry about synchronization issues: the database is shared, and changes are sent to everyone in real time. Think Google Docs, but for linguistics.
- Mobile devices supported: the UI has been designed so that mobile devices can use the app without issue.
- Pluggable machine learning assistance: any step of the annotation process, from speech recognition to tokenization to annotation, can be performed by a machine learning model if it has been deployed and configured with an instance of the app.
- 3rd party interfaces: while Glam will include some general UI for editing, there are some kinds of annotations (e.g. syntactic or semantic representations) which will be hard to annotate using general-purpose UIs. For these cases, I plan to implement an API which developers will be able to use in order to implement their own UIs that they can then integrate into Glam. Doing this will require only knowledge of JavaScript, and will let people implement bespoke annotation UIs without having to worry about all the rest of the app.
- Open source, always: I plan to keep the code open source and free forever. It’s available here: GitHub - lgessler/glam: (WIP) a webapp for language documentation
Problems
There are problems left to be solved, of course. A few of the standout ones:
- Deployment: the nice thing about web apps is that end users get the app by just typing in a URL instead of having to putz around with installing something on their computer, but the bad part is that every project needs to have someone with enough technical know-how to set up a web server. I don’t have much to say about this for now, other than that I plan to make deployment as simple as possible. (For the techies here: Glam compiles to just a single .jar file, which can then be run behind a standard web server like Apache 2.)
- Import/export: this is a thorny issue for any app. My plan is to accept as many common input formats as possible, and to, at least at the beginning, export data that is in as transparent and usable a format as possible. (Highly demanded export formats might be implemented by Glam, too, and of course, code contributions for implementing imports/exports will always be welcome.)
- Internet required: when I first started thinking about modern apps for fieldwork, I was convinced offline-only support was a must. After a lot of thought, I decided it was not technically feasible for the moment given other design constraints. This is unfortunate for people who work in conditions without reliable internet, though internet connectivity is becoming increasingly common, and there are ways of bringing low-cost, low-power servers into the field to provide services like Glam: Nick Thieberger used a $100 Raspberry Pi to power a web server for distributing archival material, and I suspect similar approaches might work for Glam.
- A/V support: In its first versions, Glam will not support ELAN-style annotation of audio and video. I know this is a very important feature for most fieldworkers, but this is out of scope for the very first releases. The good news is that while it will be time consuming to implement, there are no technical obstacles or puzzles to achieving it, so it will hopefully just be a matter of time.
Conclusion
I hope at least some of these ideas are exciting, and I’m looking forward to any comments you all might have. Please leave a reply, and if you’d like me to keep you posted with development updates please let me know. You can find the code here: GitHub - lgessler/glam: (WIP) a webapp for language documentation
 .
.
 (Gotta annotate those sentences!)
(Gotta annotate those sentences!)