Here’s a pretty interesting (if in-the-weeds-technical ![]() ) article about the JSON data exchange format, and how it seems to be “beating’ XML. The graph pretty much tells the whole story:
) article about the JSON data exchange format, and how it seems to be “beating’ XML. The graph pretty much tells the whole story:
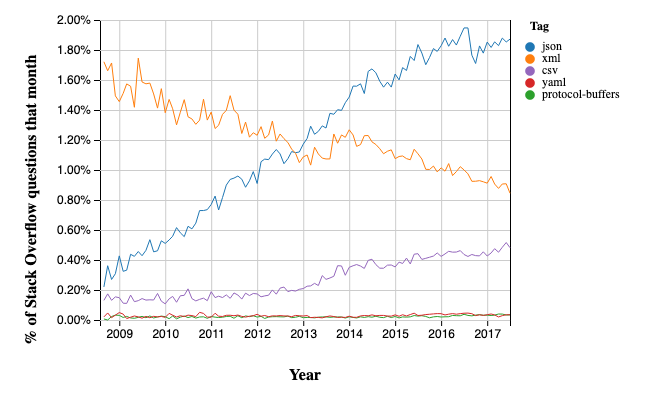
I think the key difference is right in the expansions of the acronyms (ah, techies and their acronyms ![]() ):
):
JSONis an object notation (and theJSbit is actually misleading!).XML(likeHTML) is a markup language.
I think there’s a good argument that we should be using JSON for documentary data, at least going forward. As @BrenBarn pointed out to me (personal communication ![]() ), one of the advantages of
), one of the advantages of JSON is that it’s typed. This is important for data, because we often need to distinguish numbers from text. Let’s imagine a (rather naive) representation of a single Spanish word:
{
"id": "1234",
"syllables": 2,
"form": "kasa",
"gloss": "house"
}
For some reason this project is documenting syllable count. Whatevs. But note that the number of syllables, 2, is not quoted. That means (to a JSON parser) that it’s different from the value of the id property ("1234"). Because you know it’s a number, you know that doing things like, say, taking an average of all the words in some list would be a meaningful thing to do — taking an average of the ids would not!
XML makes that harder. Here’s some roughly equivalent imaginary markup:
<word>
<id>1234</id>
<syllables>2</syllables>
<form>kasa</form>
<gloss>house</gloss>
</word>
Of course, there are a million ways you could indicate that you want the syllable count to “be” a number. You could add an attribute:
<word>
<id>1234</id>
<syllables type="number">2</syllables>
<form>kasa</form>
<gloss>house</gloss>
</word>
You could use a custom tag:
<word>
<id>1234</id>
<syllables>
<number>2</number>
</syllables>
<form>kasa</form>
<gloss>house</gloss>
</word>
I’m just making this markup… er, up. But consider: every choice about markup means writing code to interpret that markup. You have to write code to do anything with JSON too, but you don’t have to write as much for this very common kind of thing.
After all, ultimately parsing any data — markup or an object notation — is going to end up in the hands of a programming language, and the “native” representation of this kind of stuff in a programming language is going to need to have the right representation anyway. So, suppose you wanted to use Javascript to parse that bit of XML:
let xml = `<word>
<id>1234</id>
<syllables>
<number>2</number>
</syllables>
<form>kasa</form>
<gloss>house</gloss>
</word>`
let parseWordXML = xml => {
let dom = new DOMParser().parseFromString(xml, 'text/xml')
let word = {}
word.form = dom.querySelector("form").textContent
word.gloss = dom.querySelector("gloss").textContent
word.id = dom.querySelector("id").textContent
// one of these kids is doing its own thing:
word.syllables = parseInt(dom.querySelector("syllables number").textContent)
return word
}
But guess what the output of actually running this custom parsing code is going to be?
let word = parseWordXML(xml)
/* the same as the JSON… */
{
"form": "kasa",
"gloss": "house",
"id": "1234",
"syllables": 2
}
Markup is great as an ouput format, especially for complicated document formats (think of the rather terrifying TEI).
But it’s not great as a data exchange format, since you’re going to have to parse it anyway, and it’s going to end up being pretty much equivalent to JSON anyway!