Split this off from @Sandra’s comment in the data format thread because it’s really a worthwhile thing for us to talk about. (Both @nqemlen and @clriley might interested in this too.) Nick and I were making use of the OCR’d content available on the Internet Archive, which is surprisingly good for Old Spanish and Aymara, but as Sandra mentions, the Internet Archive’s actual software that does the OCR is closed source.
Hoping others will jump in here, but by way of getting the ball rolling I’ll mention one interesting online demo that I actually use on fairly frequently for small jobs, just because it’s so idiot-proof:
It’s not terribly intuitive as a website, but you can actually drag-and-drop an image onto that page and it will run OCR on it and spit out the results. Surprisingly, the whole thing is run in the browser (it’s Javascript). So that’s a thing.
Have you used OCR to deal with legacy print materials? How did it go?
Does this run the same OCR as the tesseract package you can run via python? That’s what I tried. It did fairly okay, but as all the diacritics were definitely too much for it.
Yes, it’s tesseract underneath, via a weird thing called Emscripten which can take non-Javascript code and make it runnable from Javascript. Kind of black magic to me, no idea how that works.
It is apparently possible to train tesseract to recognize other writing systems, and there are also existing modes available for a lot of languages. @nqemlen and I tried the Old Spanish model on the 17th century Bertonio Aymara/Old Spanish corpus. It did help recognize some of the Old Spanish characters that the default (English, I guess) model missed. But it didn’t have the page layout recognition that the OCR on the Internet Archive had, which we needed. Alas.
I do think for a lot of corpora, training tesseract could definitely be worth the effort, but it’s not a trivial process.
For the colonial Aymara project that @pathall mentioned, OCR is important because the corpus is at least 200,000 words, so we could never transcribe it all by hand. We’ve been working with a system called Monk (http://monk.hpc.rug.nl/), which was created by computer scientists in the Netherlands to run OCR on handwritten manuscripts (mostly from the Dutch golden age), which I think is amazing.
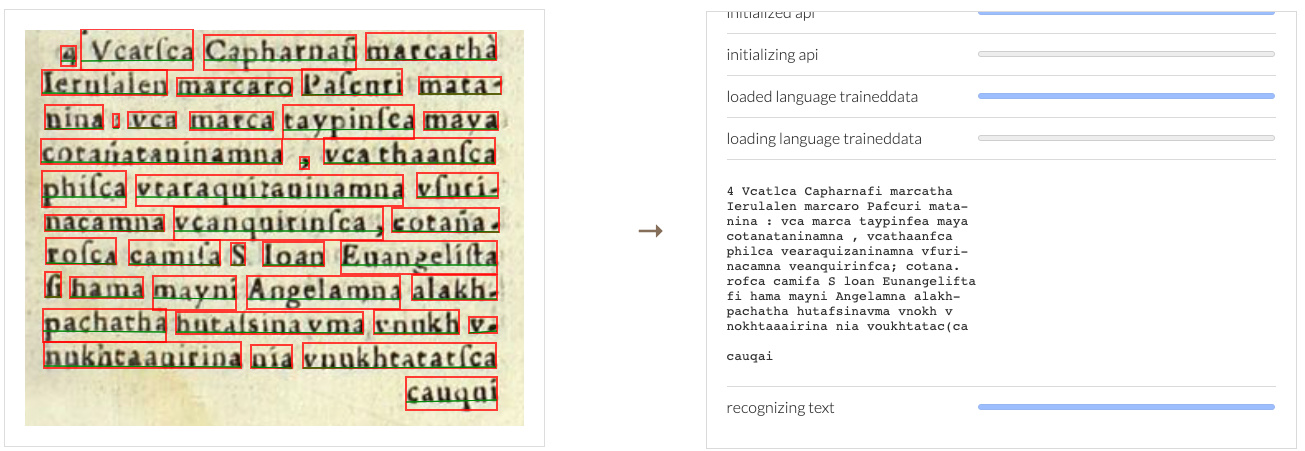
But Tesseract also sounds really interesting. Actually, I just tried a passage from the Aymara document at the page Pat sent, and I was surprised by the results. They’re much better than Internet Archive:
It seems like some very basic training would solve the errors (for instance, which orthographic symbols do and don’t exist, and in what combinations). Do you know if it’s possible to do that kind of training? I have at least 20,000 words already transcribed, which seems like a robust training corpus.
Nick
As for training Tesseract, it’s been a while since I have looked into it, but it does look like the docs have developed, but it still looks pretty hairy:
After some brief browsing and rumination I’ve come to the conclusion that OCR fills a different role for the digitization of linguistic data when compared to the prose data that it is typically used for.
One issue is training and dataset size. OCR is most accurate when trained on a dataset that resembles the data to be processed, but there is wide variation in terms of published linguistic transcriptions, so often a new model would need to be developed for each dataset (if aiming for high accuracy in the OCR output). Most lexicons/dictionaries use a language-specific orthography of some kind, for example, so this means that the approach to OCRing linguistic data will vary from dataset to dataset.
A second issue is accuracy. We really would want the accuracy of any digitized linguistic data to be as close to 100% as possible, more so than with digitized prose, but also prose can be improved through post-OCR NLP methods in ways that linguistic data can’t be. This means that any OCR’d linguistic data will need to be manually checked.
An approach could be the following:
A. If there is a lot of data
Train a model
Run the model
Check the output
B. If there is not that much data and there is meta-linguistic prose in the document
Try using the OCR model for the prose language on the whole document
Manually check the output for the linguistic data
If the output for the linguistic data is not accurate enough for easy manual checking, use a second model of a language with an orthography that more closely resembles that of the linguistic data, then manually check that output of the linguistic data and manually combine it with the first output of the OCR’d prose
C. If there is not that much data but no meta-linguistic prose
Use the model of a language with an orthography that resembles that of the linguistic data
just wondering if there have been any developments on this recently? I’m thinking about running ocr on various fieldnote pdfs to increase searchability (particularly for the English annotations)
Some years ago, we used Tesseract to OCR a dictionary, the developed a rule-based system to parse out the fields. Some character errors could be automatically fixed based on the misrecognizing a1 as an l. But the real problem was when fields were distinguished by bolding, which T didn’t even try to recognize. (We later experimented with ways to distinguish bold from non-bold, but have not yet combined that with OCR. ).
@inproceedings{maxwell-bills-2017-endangered,
title = "Endangered Data for Endangered Languages: Digitizing Print dictionaries",
author = "Maxwell, Michael and
Bills, Aric",
booktitle = "Proceedings of the 2nd Workshop on the Use of Computational Methods in the Study of Endangered Languages",
month = mar,
year = "2017",
address = "Honolulu",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W17-0112",
doi = "10.18653/v1/W17-0112",
pages = "85--91",
}