Hi all — following my ComputEL talk this morning, I had some interest in an interface for interactive audio classification (e.g. for language identification, speaker diarization, etc.) with the help of speech embeddings and a (trainable) classifier. Just putting down what I was thinking about to get some feedback/ideas…
About the frontend, I made a very crude/quick mock up of the interface I was envisioning in in R using Shiny:
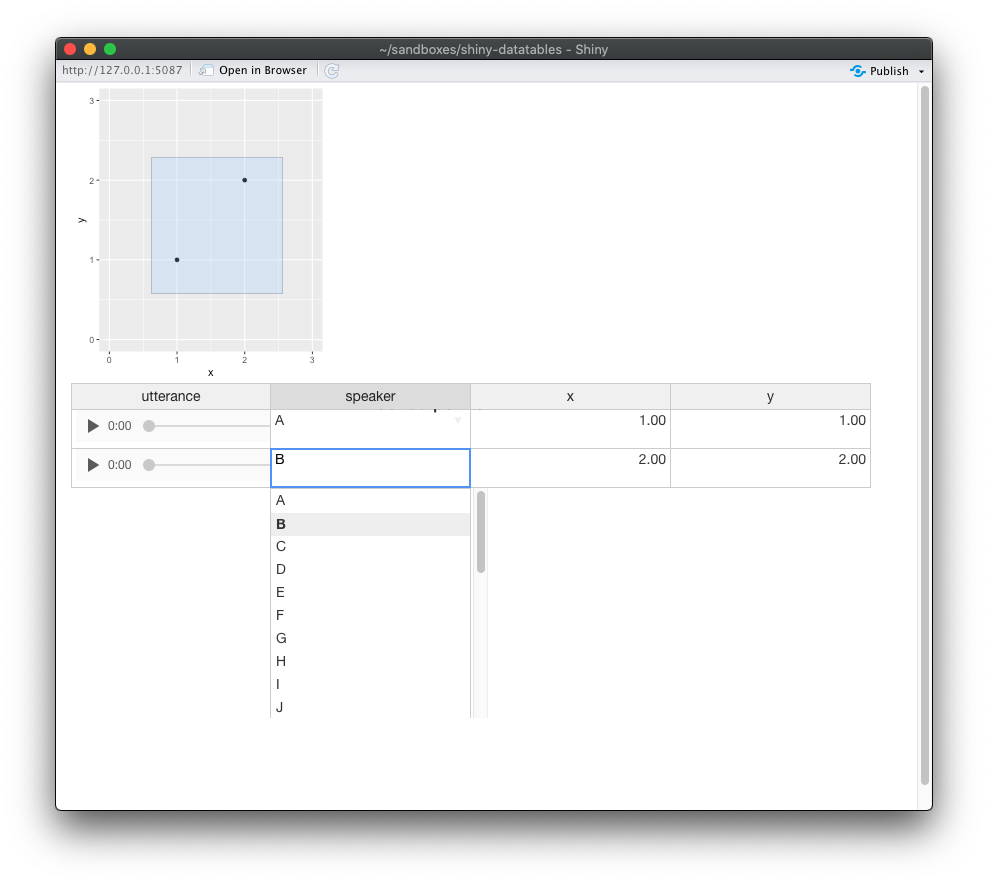
Basically you can select a bunch of points using a box (or a sophisticated lasso tool in d3.js, if that’s possible) and for each of those points you can correct machine-assigned label(s), e.g. speaker. Or there could be a checkbox and then a button ‘Label all as A’, for example.
About the backend (if you’re curious), you can extract speech embeddings using a pre-trained model like SpeechBrain and cluster them with SpectralCluster (for speaker diarization, for example). You can reduce the 256-dimensional embeddings into 2D space using a technique like multidimensional scaling.
Thoughts welcome!