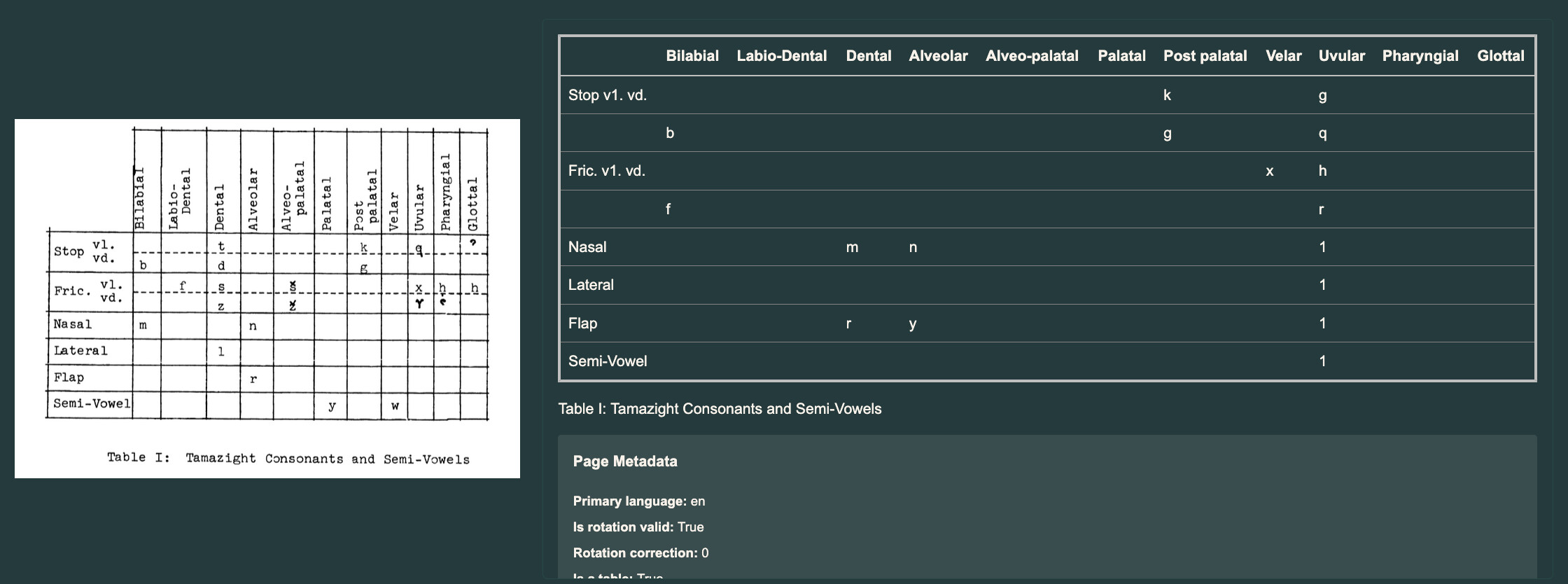
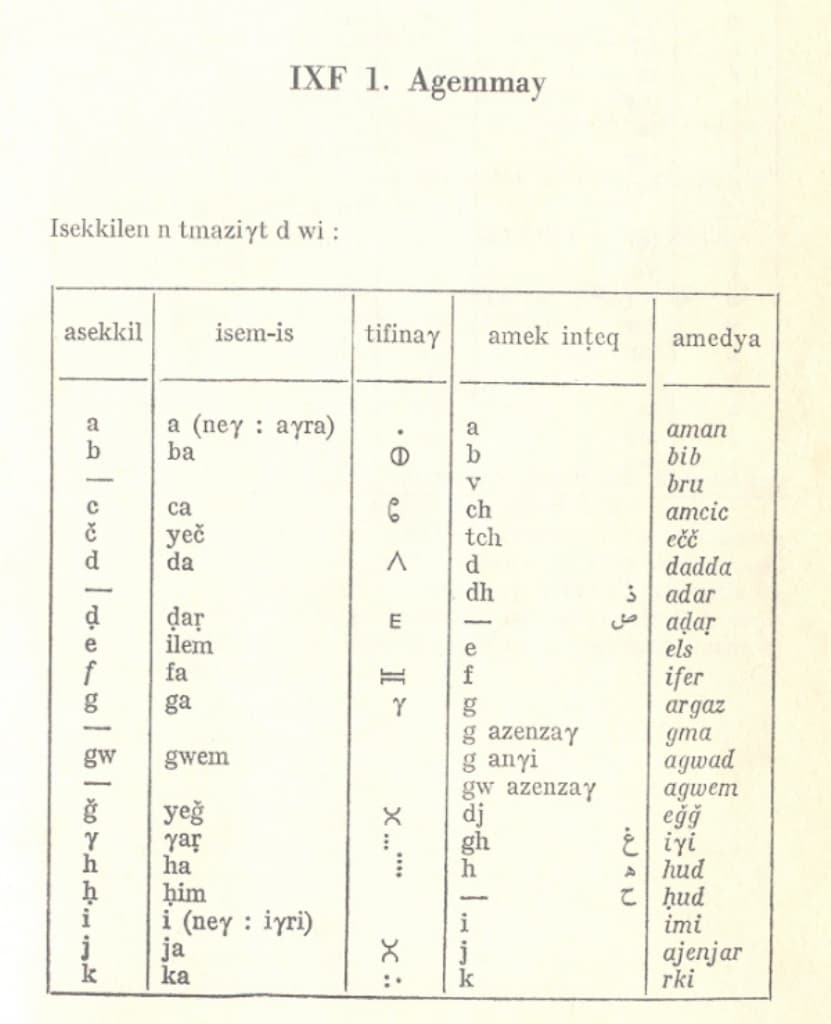
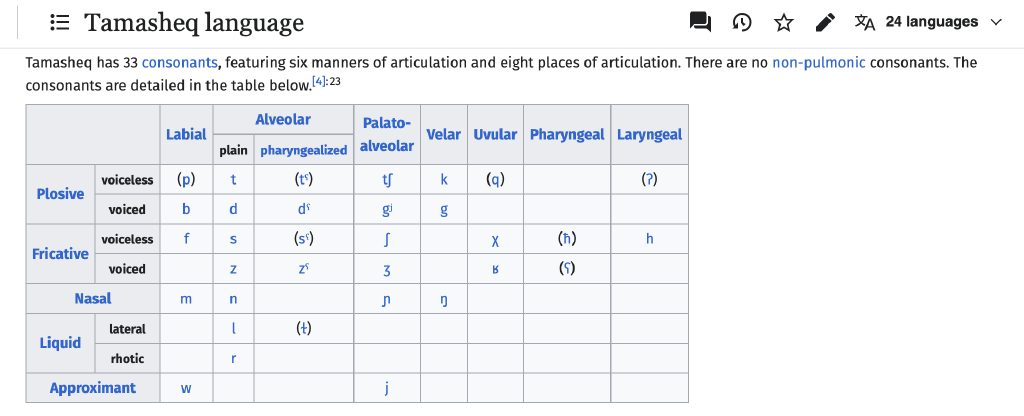
abaku
a’bachenggipa, (dakchen ningpa ; gital). a beginner ; a novice ; a pioneer ; abori- gines ; primitive ; origin ; fundamental ; primyrya. aboriginal ; primitive ; be- ginning. a’-ba chenmting. inchoate. just begun ; rudimentary. (বিল) শিক্ষা করা। (বি আশা বিন্দ আবহাও।…সত্তা বিন্দাক্ষর ; উপাধিবিন্দ ; বিন্দ)।
A’bakun, n. (dakgni ; kam ; kamtang), a duty ; a work ; means of livelihood. v. A’bakun gaa, (kam janga ; man’oroa). to progress ; to improve. n. progress ; improvement A’bakun gaata, (kam jangata), to further ; to promote ; to help forward ; to assist. (বিল) অধ্যয়ন ষোলিত। (বিল) উপাধিবিন্দ। A’banggir, n. (gamtchi gipa ripok jatsa), a blue crystal. bead necklace. নাবি কৃত্তিকমিন হার।
Abastro, n. (tinggro, longitude, আব্যান)। A’se, v. (A’a be-waka ; dare ruu), to fall off, as land ; to be detached and fall. n. landslip ; falling of land. (বিল) নালি চড়া, নালি চড়া। (বিল) পুরা-তলানা।
A’bel, n. (A’dubak ; dipo A’taru), deep mire; mud ; bog ; soft ground ; slough (বিল) কৃত্তিকমিন। লোগো কৃত্তিকমিন।
A’belati, n. (a-chi gipok), clay ; china clay. (বিল) আচিকমিন। চীনা কালি।
A’ben, n. (A’ara ; ro’onggi a’n), loam ; soft earth ; stoneless earth, (বিল) পলন; কৃত্তিকমিন।
A’bang, n. (A-chik songi salgpengi jo don gipa A-chick hende). Garos living in the southe rn portion of the Garo land ; A’bang aro. the region where A’bang man lives. (বিল) নাবি ভাষার পক্ষে শাস কবা চীনা ভাষার সম। তাদের মা।
Abet, n. (kori ; betbetgipa ; agandipetgipa), a talkative man ; an evil. -a. garrulous; talkative (বিল) কথা প্রকাশ করেন। (বিল) ক্ষতিকারক। n. Abet-Rangge, an evil spirit হালি নিদাশী। adv. abetabet, (jingring). repeatedly ; frequently ; unnecessarily. (বিল) চীনা চীনা অপরাধ।
Abi, n. (abitang abigipa) an elder sister ; my elder sister ; (বিল) কথা। কথা কথা ano-abi. (noabi), sister ; কথা কথা nouab, a cousin sister. নুবো বা কন্যার আনুগত্য।
A’bibia, n. (a’ani biba ; a’oso), bad smell, that emits from the decomposed matter in earth ; atmosphere, (বিল) দাঁতি ধার বলিয়া দেয়। পুরুষ কথা মারু।
A’bibak, n. (a’banak ; a’ganguri), the north or south pole. (বিল) উত্তর বা দক্ষিণ দেয়।
A’bibol, n. (a’bima), the globe ; the Earth ; the World ; a ballshaped object ; (বিল) লোকাধি পৃথিবী ; পৃথিবী পৃথিবী।
A’bibrom, n. (a’ba a’gilsakai ga’brong), the exis of the Earth. (বিল) পৃথিবী অফ।
A’birding, n. (a’anding ; a’rikging ; a’ginda reng), ridge ; range. ডাব। (বিল) ফায়র আদিন।
Abigipa, n. (abi ; abitang, an elder sister ; my elder sister. (বিল) কথা কথা।
A’ibka, (a’-bi-ka), n. (a’galbang a’knings the heart of the Earth. (বিল) পৃথিবীর পৃথিবী।
Abilik, n. (bilik jatsa), a genus of bean. (বিল) পৃথিবী অফ।
Abim, n. (jongdanggap jatsa), a kind of worm, that can roll itself into a ball. (বিল) সাত সাত। পুরুষ পুরুষ। এতেব পুরুষ।