Stumbled across this this morning:
https://www.mpi.nl/corpus/html/elan/ch03s05.html
I’m curious if anyone here has tried it. If so, what did you think?
Just spent like 45 minutes trying to gloss ten words. Did not succeed.
Glad to see this. I need to try it now.
1 Like
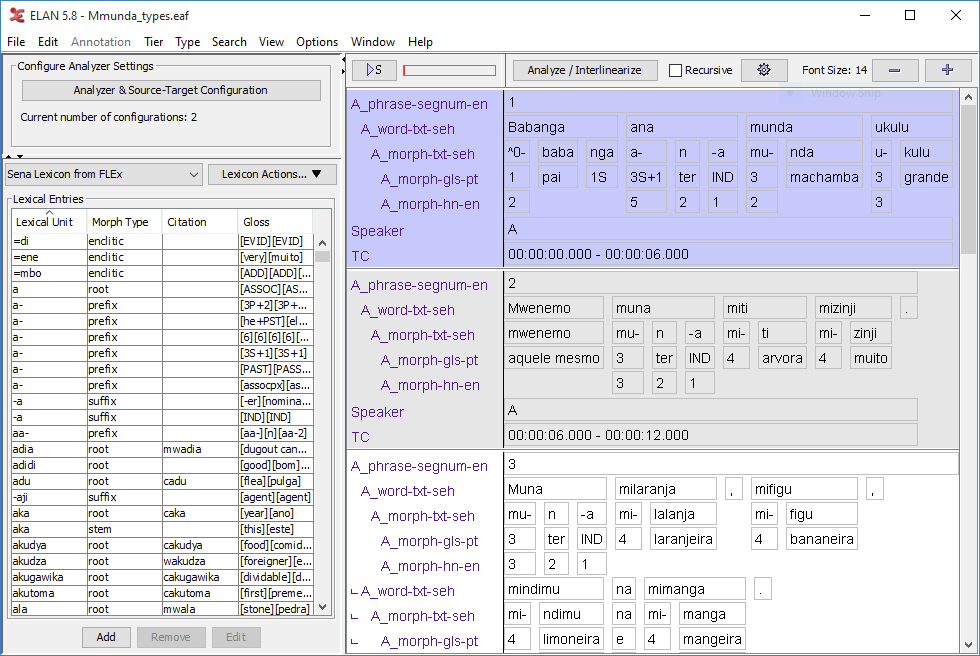
I’ve used it with some minor success. As you might expect, it isn’t as good as FLEx’s interlinearization capabilities. Some limitations I encountered:
- Changes to the lexicon are not implemented in the EAF data created using that lexicon, so you need to manually implement each change you make (e.g. a new gloss) across all of the files in your corpus.
- Tonal constructions aren’t recognized and tonal data isn’t considered separately from segmental data (not fully supported in FLEx either, AFAIK). This was a big problem for me actually and resulted in multiple entries for the same morpheme with different tone.
- The ELAN interlinearization system “learns” which potential interlinearizations are most likely to be correct, but still isn’t very good at it. It can produce a very long list of possible matches/permutations, and the correct one is sometimes hidden somewhere in the middle. It doesn’t appear to be sensitive to the lexical class of the root in determining the probability for a given affix (e.g. a nominal suffix never attaches to a verb).
IMO FLEx is still better for the interlinearization of large datasets and ELAN is still better for time-aligned data. You can use them together, of course…
2 Likes