Outside letters of evaluation solicited from senior scholars
Assessment criteria
One of the issues that remains to be addressed is how assessment of materials would be done. What makes a good documentary record? The early LD literature was largely focused on establishing ideals for documentation and less on how documentary outcomes might be assessed. Some potential criteria could include the following:
Comprehensiveness
The number of speakers in the record
The percentage of the total number of speakers in the community
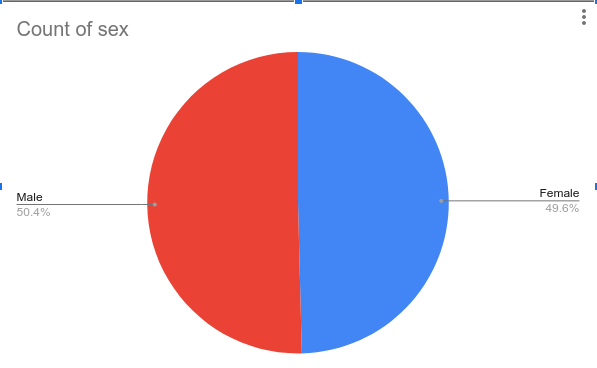
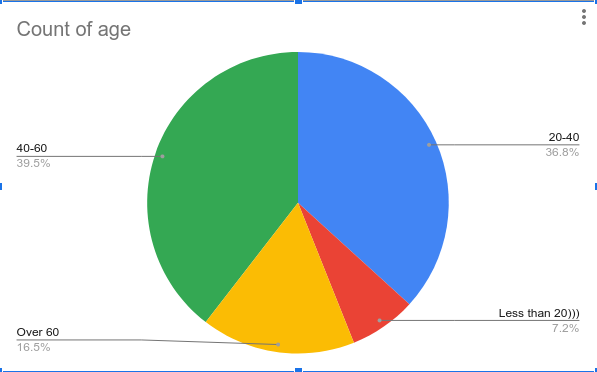
The proportion of speakers by sex and age
The number of data collectors and the proportion of data collectors by sex/age/community membership
The number of hours of audio-visual materials
The quality of the audio-visual materials
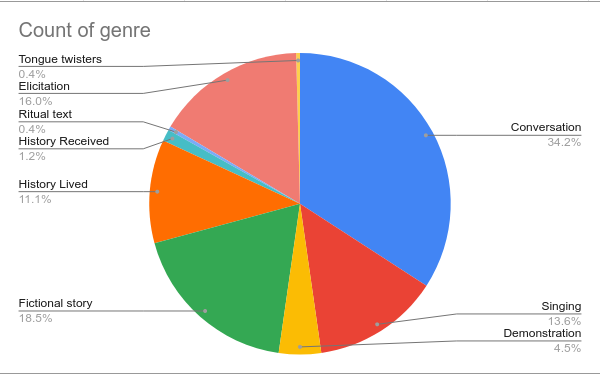
The distribution of speech genres
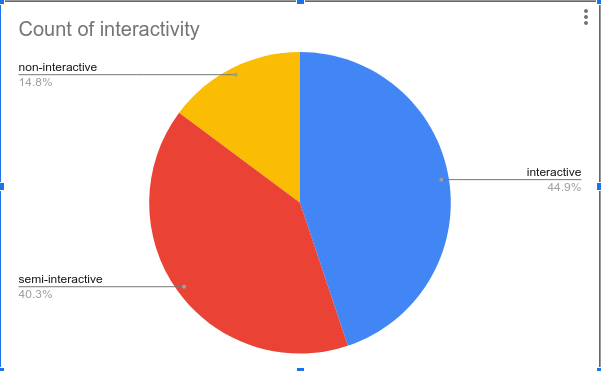
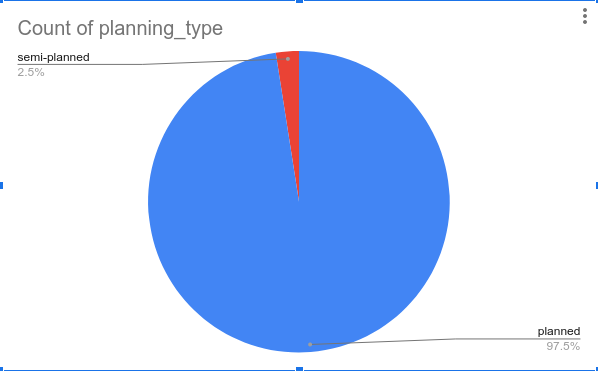
The distribution of interactivity and planning types
Research Accessibility
Metadata for each speaker and recording
The percentage of materials transcribed
The percentage of materials translated
The percentage of materials interlinearized
Community Accessibility and Involvement
Did the community contribute to the creation or evaluation of materials
Is the archive available through an interface in a language that the community can read
If community can’t access the archive, were materials distributed to members of the community
Peer review process
Of the options presented by LSA, my favorite is probably #3, except that in Haspelmath and Michaelis’ format it removes the archive from the peer-review process and rather focuses on the assessment of secondary corpora developed using archive materials. So here is my alternative proposal:
Language archive journal: Curators of archive materials submit to the journal to argue for the value of their materials. Submissions must include required information about the materials, such as the criteria above, as well as prose descriptions of the process through which the materials were created, their potential for research/community use, and any reasons why the materials may not meet some of the standard LD criteria.
As it is currently, archive materials are often only subject to peer review through internal assessments conducted by archives/funding agencies. External peer review would (mostly) remove conflicts of interest and increase the incentives to produce high quality materials.
The only other external peer-review process for archive materials is the DELAMAN award, which is great, but is kind of like having a journal that only publishes one article per year and we all need to compete to be the one who gets published.
There is also some value in allowing for the peer review of archive materials at different stages of development. For example, there could be different submission categories such as early development materials and late development materials.
I think there are some journals that would be open to this (LC&D and Lang Doc and Description come to mind), but the stumbling block has been finding people who will take the time to write these reviews.
The success in getting archive materials included in recognition of research has been happening on a national level in some places through different mechanisms. I believe archives can be included as part of a REF submission in the UK, and in Australia archives can now be included in the “non-traditional research outputs” (NTRO) process where archives are assessed internally but then count towards the university’s research outputs.
A good article on this topic (from the Australian perspective): Thieberger, N., Margetts, A., Morey, S., & Musgrave, S. (2016). Assessing annotated corpora as research output. Australian Journal of linguistics, 36(1), 1-21.
Thanks @laureng for the reference - I had not seen it before! I’m happy to see that they came to a similar conclusion:
The fourth proposal that has been made for providing academic recognition for
corpus compiling and annotation is what we have called the peer-review of a corpus
and which we conceive as being parallel to the peer-reviewing process of traditional
research outputs such as books or journal articles. It is in many aspects akin to the pro-
posal made by Haspelmath and Michaelis with the crucial difference that we conceive
of ‘publication’ as taking place within the repository, therefore not only providing
acknowledgment for the compiling of corpora but also their archival curation. (p. 11)
One difference that I see between what I had in mind and what they proposed:
Review is conducted by a national or regional organization (e.g. Australian Linguistic Society) rather than the editorial team of an international journal
They also provide nice examples of how assessment of materials would need to be context-dependent. I still see some benefit in having an international journal to establish assessment standards for LD materials more generally, rather than materials specific to languages of certain regions or produced by researchers working for institutions of certain regions. Perhaps they see the path towards recognition from established authoritative bodies as an easier one than the path towards establishing a new authoritative body?
I would also qualify my earlier post by saying that corpus overview articles and corpus reviews are valuable contributions to the development of language archive standards and they all can complement each other in the ecology of research assessment.
Thanks for your thoughts on this timely topic, @rgriscom and @laureng.
I’d like to discuss the sub-topic of corpus overview articles:
There seems to be something of an emergent use of the term “guide”, at least on LD&C, to refer to these kinds of articles. There are five hits that come up on a search for guide -review (excluding review because it turns up other lovely things like reviews of @cbowern’s fieldwork guide).
This is a lot of content to look through, but a cursory glance at each of them (one of which is @laureng’s seems to be reasonably close to the corpus overview as described above:
It would be interesting to collect more such examples (I wouldn’t be surprised if there are other, similar articles that happen to not use that term.)
Slightly orthogonal to the issue of articles themselves, I wonder how much of the sorts of metrics of coverage that you describe might be generated automatically from a granularly digitized version of a corpus. I can imagine a sort of “dashboard” interface that could chart some of them by counting things from data structures. Of the ones that seem like low-hanging fruit, I would list:
The number of hours of audio-visual materials
The quality of the audio-visual materials
The distribution of speech genres
The distribution of interactivity and planning types
The percentage of materials transcribed
The percentage of materials translated
The percentage of materials interlinearized
And possible some of the others. Some would be less amenable to an automated approach (measuring community contribution and distribution seem trickier, for instance). In any case, the idea of automating such measurements seems useful to me not only for the archiving stage, but for the fieldwork stage, because it might help in making choices about what to do next.
Yes, my understanding is that the corpus overview/guide article category is fairly well represented now but still has room to grow. The corpus review and corpus journal/language archive journal categories have not really taken off, though.
In any case, the idea of automating such measurements seems useful to me not only for the archiving stage, but for the fieldwork stage, because it might help in making choices about what to do next.
That’s a fun idea! Sort of like a training app that keeps statistics on your progress (e.g. in a sport/physical activity). You could have a set of metrics that give you a quick snapshot of where you’ve been, where you are at, and where you are projected to be in the near future given your current rate of change.
These overview articles are sometimes referred to as ‘proxy publications’ because they allow researchers to point to the cited article to stand in for the corpus in citation practice. They also allow the researcher to gain some of the academic merit that is usually associated with a journal article but still not given to publishing a corpus.
Ideally better data citation would eliminate at least the first reason for this genre. The second is more entrenched (and that’s one aim of the Trømso Recommendations for citation of linguistic data).
If you’re thinking of pushing ahead with a project on this, the Linguistic Data Interest Group might be a good space in which to organise: https://www.rd-alliance.org/groups/linguistics-data-interest-group
Most of us in the LDIG are currently focused on promoting the Trømso Recommendations, but the group is intended to be an open space for people to work on linguistic data promotion projects, using the support of the Research Data Alliance.
that might require rather better and consistent metadata than linguists sometimes provide!
Right! I imagine the same could be said for most people who use training apps or other progress tracking apps, but the apps encourage regular logging of information in exchange for the guidance and positive feedback that they provide.
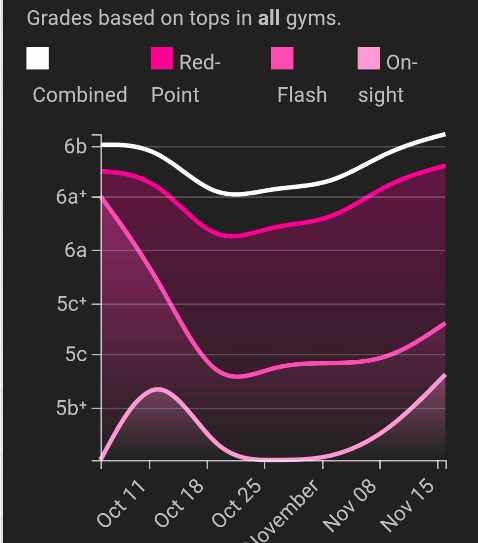
Here is an example of a rock-climbing training app which takes as input the routes you’ve completed, how you completed them (On-sight = first try without hints, Flash = first try with hints, Red-point = second try or later), and their difficulty rating. It creates a graph for each user, showing their progress over time. Prior to using this app I never once created any metadata about my climbing, but now I log the information each time I climb.
Quick feedback would probably be easiest with born-digital metadata, entered into a computer or mobile device. Just for fun, here are some metadata snapshot stats from an unidentified ongoing project:
The number of hours of audio-visual materials: ~25
The quality of the audio-visual materials: HD video (.mp4) and 24 bit 44.1khz audio (.wav)
I imagine the documentary corpus tracking app would say “good job on the audio-visual materials and speaker distribution, but you probably need to start increasing your rate of producing text data if you want to reach your target goal by the end of granting period”
Thanks for the link to the Interest Group! I just joined, and in the process discovered that I already have an RDA account .
There is a related project that may be of interest to those in the group (and here). I’ve been working with the Editor-in-Chief of the Journal of Open Humanities Data to design a special issue on the assessment of language documentary materials. I imagine it could include a) peer-authored reviews of materials, b) articles discussing assessment criteria and the review process (e.g. as in Thieberger et al. 2016 or with a more granular focus on individual criteria), and c) curator-authored guides/overview articles. It would be great to get more feedback on the scope and design of the issue, so perhaps I will make a separate post with more details. There is also room for another guest editor or two.
 .
.