A lot of attention has been given to minimizing the transcription bottleneck associated with processing natural speech texts, perhaps because it is a good problem for AI/ML to solve. Much less attention has been paid to minimizing the manual processing tasks associated with linguistic elicitation, which for many linguists often include manually segmenting audio and either copy-and-pasting text or directly typing text into an application like ELAN or Praat.
I’ve previously tried to get at this problem by creating audio which can be more easily automatically segmented (e.g. using “Voice Activity Detection” or a function like Praat’s “Annotate to TextGrid (silences)”). This requires training speakers to produce elicited items in a very consistent manner, maximizing the signal-to-noise ratio (e.g. using a headset microphone), and creating a recording specifically for productions of elicited items with no metalinguistic information. It also helps, of course, if you create digital data directly by typing transcriptions into a spreadsheet app rather than writing by hand. Putting the timecode data and the text data together still requires a separate processing step, however, and not all speakers are good at producing repetitions consistently, which can result in segments of audio which contain mistakes being parsed by an automated system and also restricts the method to only those speakers who have a natural aptitude for elicitation.
Enter the linguistic elicitation web app. It’s actually a very simple idea, and I imagine that anyone reasonably familiar with web programming could put it together in just a few hours. Here are the basic features:
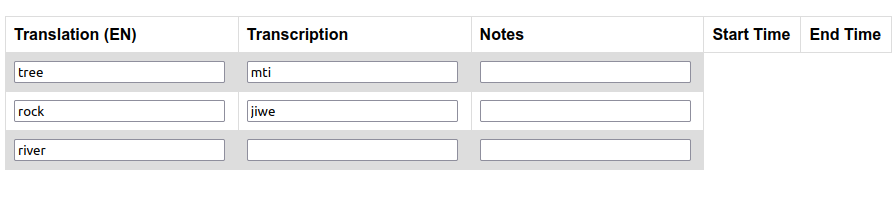
- A dynamic spreadsheet-like table with form boxes, something like this quick mock-up I made:
- The ability to add and remove columns/rows using buttons.
- A CSV/JSON import function
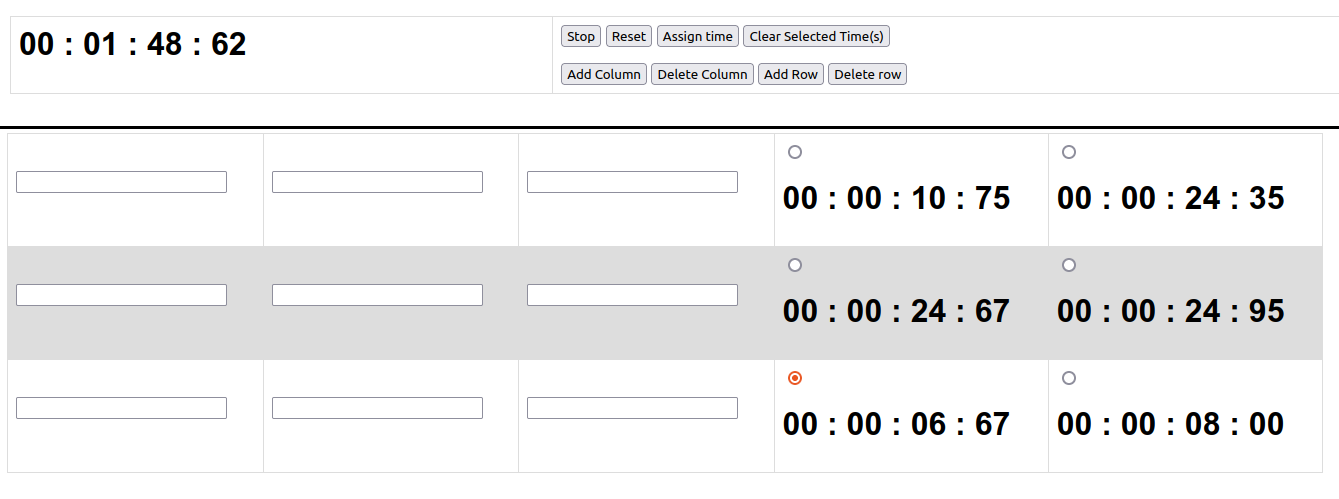
- A stopwatch/timer function. This is the critical piece! The user starts the timer the same time they start the audio recording, so that they are more or less synced together (with a degree of accuracy sufficient for the task of aligning text at the utterance/elicited-item level). The standard start/stop + resent buttons should work, perhaps with a confirmation dialogue if you want to stop or reset to avoid mistakes.
- An “insert time” function which takes the current time and inserts it into either the start time or end time. This creates the timecode data for each utterance. Ideally this would automatically advance, so that if all is going well the linguist simply hits the “insert time” button before and after each utterance/elicitation item.
- Critically, the user also needs to be able to remove timecode data in the event that they want to redo an item.
- If the speaker produces a slight variation of the target data which the linguist finds acceptable (and thus not requiring a total redo), they can directly modify the transcription. This should be done in the moment, not at a later time.
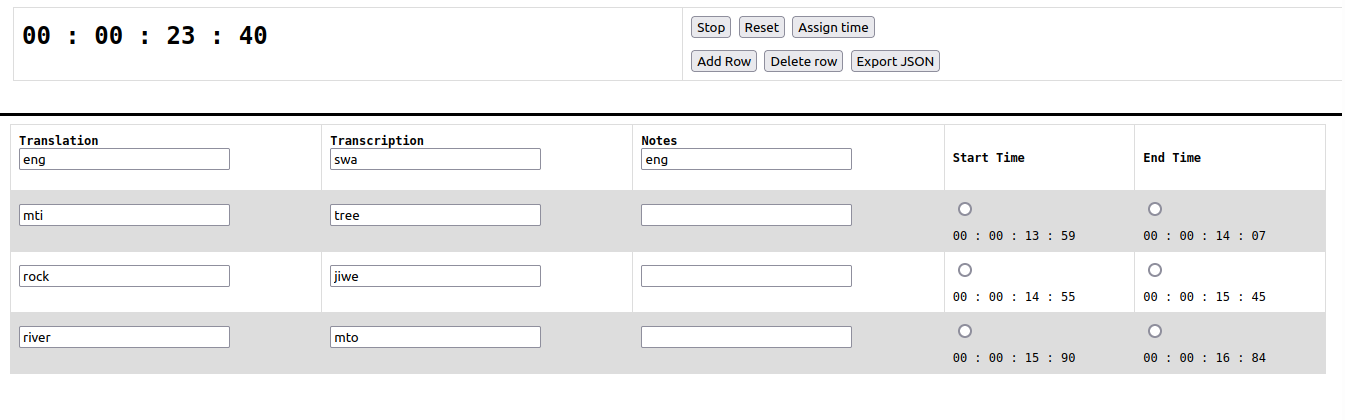
- An export function which can produce CSV, JSON, .eaf, .flextext, and .TextGrid based on the data entered into the forms.
- An adaptative/responsive design which makes it possible to use the app either on a computer or a mobile device
What’s cool about it
The first cool thing about this method is that after you have exported your data there are no more steps. Aside from transferring your audio recording to your computer, you are done! You can literally open the .Textgrid/.eaf/.flextext immediately and run searches across the time-aligned data.
A second cool thing about it is that it doesn’t require specialized training for the speaker, and you can still work with a less-than-ideal signal-to-noise ratio (e.g. a noisy environment or a lower-quality microphone).
Third cool thing: you can create a recording with both metalinguistic information and linguistic data together, without having to worry about distinguishing between the two.
Finally, a fourth thing that is cool about it is that you can use the same app on either a computer or a mobile device with a bluetooth keyboard. This is really critical because it makes it possible to use the method literally anywhere in the world.
The take home message
This could have big implications for fieldworkers and field methods courses, and would strongly encourage descriptive linguists to adopt reproducible research practices (e.g. making their primary data available).
It also should be relatively easy to create…so who wants to make it with me?! ![]()


 great question
great question