Continuing the discussion from The Rift Valley Network: learning how to collaborate:
This talk by @Andrew_Harvey and Alexander Andrason describes projects related to a pretty slippery linguistic phenomenon: interjections.
A couple of points that come up in the talk caught my attention. Firstly, interjections are pretty infrequent in speech, so as Andrew notes, a corpus would need to be very large indeed in order to provide a representative sample of them. (How often does Eek! occur in English corpora, for example!) So the original plan to collect examples of interjections from transcribed texts was replaced, at least provisionally, with a creative elicitation strategy.
Here’s my lightly edited transcription of the relevant bits from the YouTube machine translation (this is Andrew speaking):
[12:31] Now it is in this context that Alex approached us wondering if we could collect some data on Hadza interjections. Because my personal orientation is sort of heavily oriented towards natural speech, I initially thought that we could build a list of interjections mainly by just going through our natural speech recordings and identifying the interjections as they occurred in their contexts. Indeed, this would be the ideal in terms of quality of data. However, very early on it became clear [13:05] that in order to build a large list of interjections we would need to be working with a very large amount of natural speech. And because this material has to sort of be translated and transcribed by our local researchers, [13:17] there’s a certain lag time. So this is still a desideratum but in order to at least make a start on the project we decided to try eliciting interjections to see if this would yield the forms a bit more efficiently.
So how does one go about eliciting interjections? I personally never attempted to do something like this. Alex provided some examples of the types of interjections for which he was looking, often responses to external stimuli or expressions of emotions. I had doubts about directly asking Hadza [13:55] speakers about what sounds they might make in certain situations, eliciting these, and so I wanted to elicit these forms as a slightly larger context i that that was sort of my preference so eventually settled on developing a long list of kind of short skits in which two willing speakers would encounter a stimulus and would react to it. So here is one example in which Gonga [14:23] the speaker to the right reacts with slight exasperation to Tchanjaiko, the [14:28] speaker on the left’s mention of an annoying foreign researcher who keeps bothering them with his silly questions
Clearly, the skit approach was successful, as the database the team built attests:
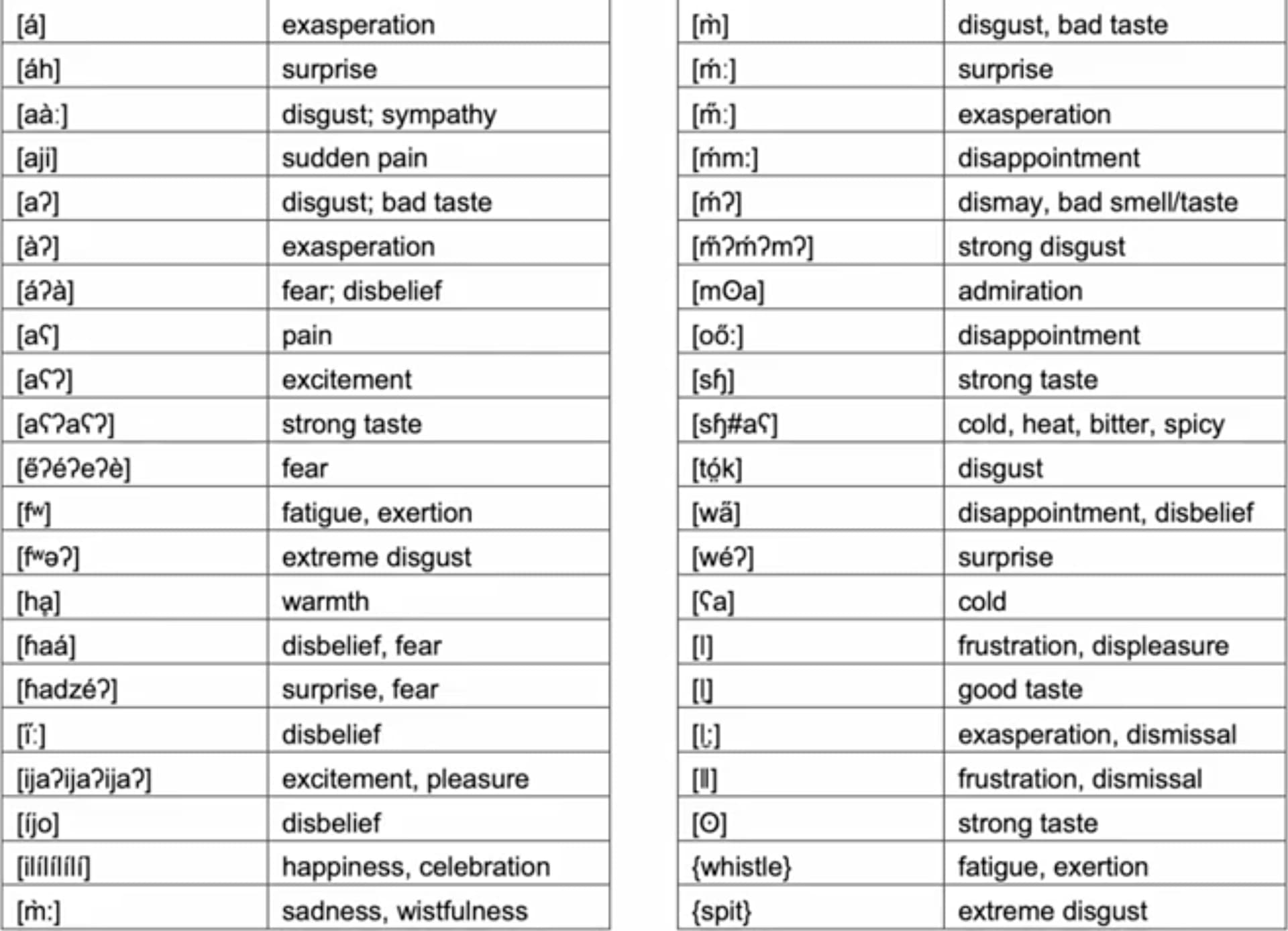
Imagining interjection interfaces
Now, there are two workflows described here, one of which was determined to be appropriate for the circumstances. I think it’s worth imagining interfaces that might have helped with both of those workflows — not because there is anything wrong with the way the work was carried out (the proof’s in the pudding! It worked!), but because designing user interfaces for documentary workflows is a skill, and skills need practice.
Workflow 1: Collect interjections from a corpus
Dataflow
Input
- A time-aligned corpus.
Output
- A time-aligned corpus with interjections tagged at the word level.
- The extracted list of such interjections.
Workflow
- Read through the corpus, annotating interjections until a new one is found.
- Tag that token as an interjection.
- Search the rest of the corpus for that form,
So let’s consider an example text, here’s one:
https://docling.net/book/docling/text/text-view/text-view-sample.html
There is a very common Hiligaynon interjection bao (at least that’s the way the speaker said it — apparently it shows up in dictionaries as abao. As the senses at the link suggest, and like many interjections as Alexander points out in the talk, it has a rather bewildering array of meanings.
So I would suggest that the simplest interface to communicate the idea “this word is an interjection!” is simply to click it. We’ll need some sort of user interface indication that a word has been selected. Here’s a very rough mockup:
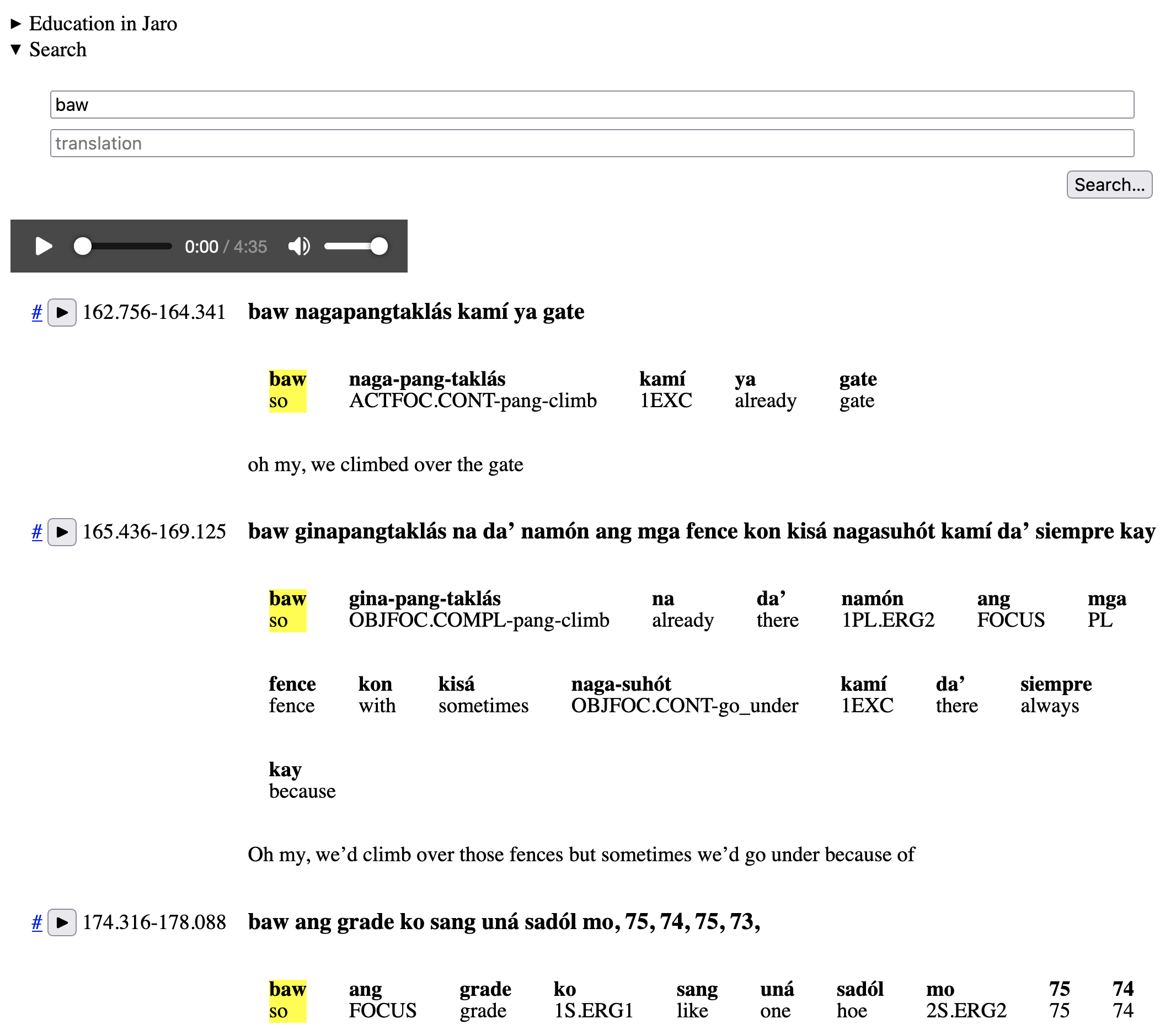
You can see the word baw with its yellow background. The user experience is very simple: click the word to mark it as an interjection (and click it again to un-mark it). Notice also that I’m using the little search box at the top to filter for sentences that contain baw. This is assuming that we already know that baw is an interjection, of course.
This is a hacked up version of the basic text view component of docling.js, which you can see here:
https://docling.net/book/docling/text/text-view/text-view-sample.html
As always, creating a mock-up raises questions (and this is part of the reason to make a mockup as quickly as possible!):
- Are we looking for tokens or types of interrogatives? In the talk above, the research seemed to be related mostly to the “shape” of interrogatives — how their phonetic segements could combine. For that purpose, you just need a list of types. If the research goal had been different (say, “what kinds of context do interrogatives appear in?”), then we would be want to collect sentences, not words.
- What is the workflow to get this interface running? We need to load the text data, we need to figure out some kind of output format. Should we modify the user interface to show the lexicon of interrogatives as we collect them? (Almost certainly!)
Here’s my own design for next steps:
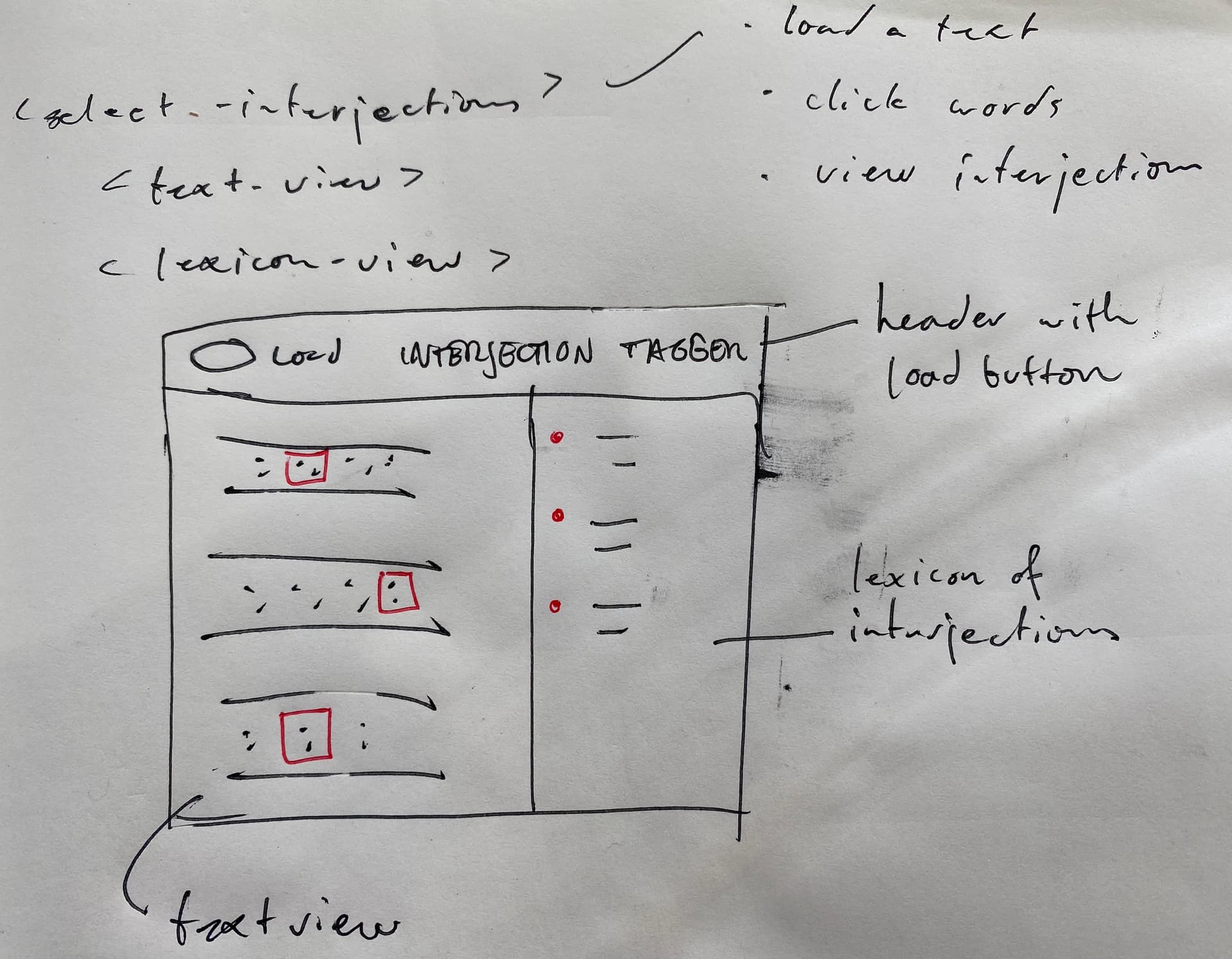
So, what do you think
Workflow 2: Elicit interjections with scenarios
This is a much more complicated interface goal (and harder to mock up quickly), but there’s no reason we can’t brainstorm a bit. ![]()
![]() .
.
(This is my own understanding of the task, if this isn’t what actually happened Andrew, please feel free to rewrite this.)
Dataflow
Input
- A list of interjection skits.
Output
- A corpus of natural speech recordings, some of which contain interjections.
- The extracted list of such interjections.
Workflow
- Write down some ideas for skits that might elicit an interjection.
- Record speakers improvising the skit.
- Mark the skits that contain an interjection.
An interesting question arises immediately: suppose we manage to collect, say, ten recorded skits. And let’s also imagine 6 of them produce an interjection. What do we want as output? A transcribed and glossed time-aligned corpus? If the goal is to enumerate the phonotactics of interjections, then that is not the right next step at all. We might even want to transcribe nothing more than one word per skit.
But maybe we think the skits are great content, and we want to try to transcribe them in their entirety. Either interface could be useful, so it comes down to goals and resources. A time-aligned transcription interface is of course a huge project — perhaps as @SarahRMoeller pointed out in the single piece of software topic, the best step would be to use ELAN…
But let’s consider the simplest thing that could possibly work: we’re looking for a tiny lexicon of interjections, and we’re managing a list of “skits”, and a list of interjections. So I would list our “entities” as something like this:
- SKIT
- description
- RECORDED SKIT
- skit
- participant list
- media files (audio or video)
- interjection list (a small lexicon)
(Note that we’re also assuming that the recordings are also done — an interface for a recording workflows would also be possible!)
As soon as one starts thinking about these things, the possibilities crack open. I’ll jsut mention two broad interface ideas that popped into my mind:
Multi-clip workflow
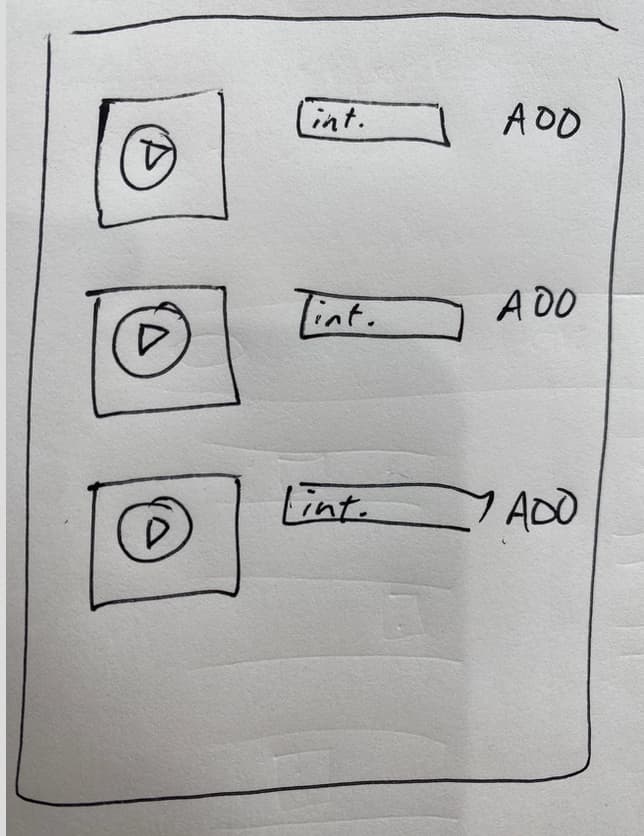
This one assumes that we have multiple media files, one per skit. The idea is that you work down through the page, playing each file as you go. If you hear an interjection, you transcribe it in the input box and click “add”.
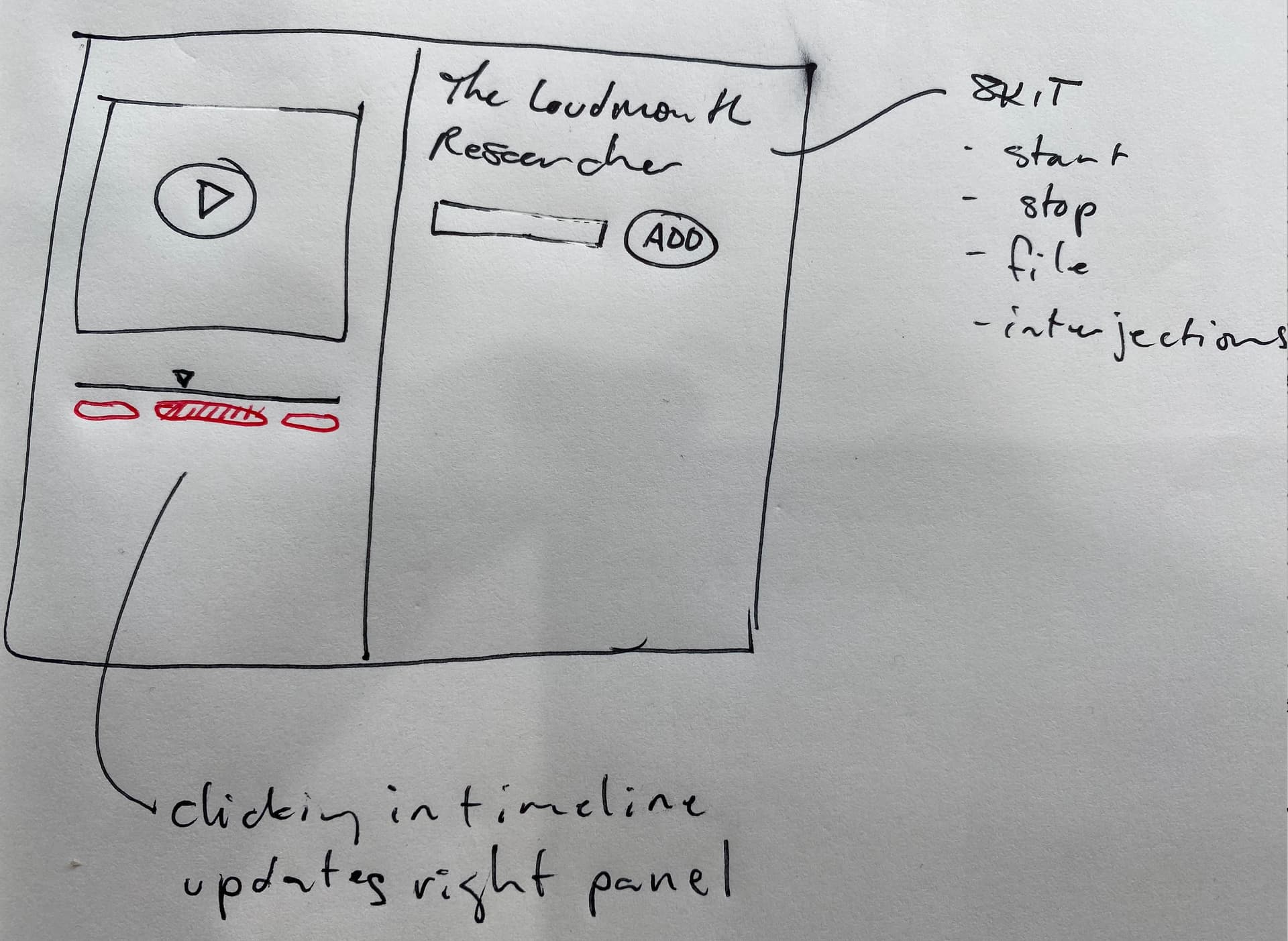
In this more complicated approach, we assume there’s a single video containing multiple skits, but that there are timestamps associated with each one. There is a navigation bar below the video scrubber timeline with a oval corresponding to each skit segment. You click on one, and then you get the title and an input with an add button in the right panel.
Do you have any other ideas? It’s also worth noting that while we are starting with a fairly specific documentary task (collecting interjections), these interfaces would be extensible to other areas — onomatopoeia could probably use the same interface, for instance.
I feel like the idea that you shouldn’t stop to worry about “level of specificity” before designing an interface is a very liberating one — just build something, with the assumption that you can generalize it or specialize it later.