I did a little procrasti-project today… you know, when you have stuff you must do, and your ![]() says “
says “![]() ! Don’t do that sensible thing!”), and you end up putting your mental energies into something else… y’all know what I’m talking about. Might as well make something of it.
! Don’t do that sensible thing!”), and you end up putting your mental energies into something else… y’all know what I’m talking about. Might as well make something of it. ![]()
I’m sure you all spend a fair amount of time looking at linguistics and language stuff on Wikipedia. It occurred to me that there is actually a fair amount of fairly well-structured interlinear text there. Wouldn’t it be cool to try to get it all into some kind of queryable form? So I had to start looking into it.
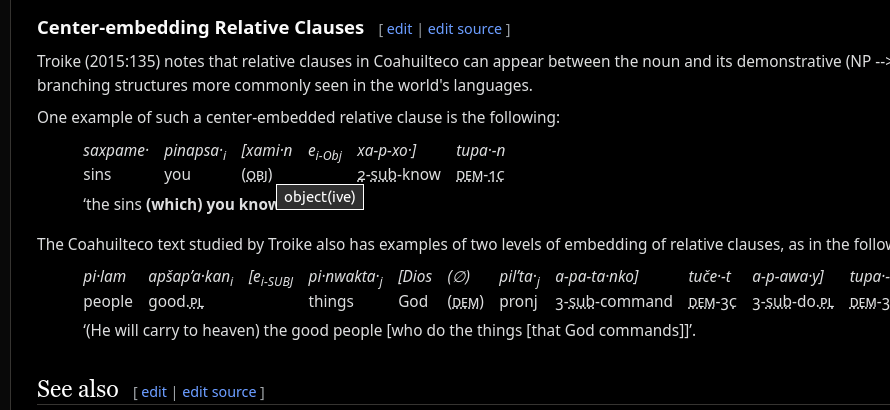
First thing was just to poke around and try to find some. I happened to be looking at the article on the language of the Shawnee people, also called Shawnee, a central Algonquian language:
There are maybe 30 interlinears on that page — not a huge database, but not nothing.
Should we scrape the HTML?
Scraping is the programming word for writing a program that picks apart the bits and pieces of an HTML page. Scraping can be painstaking or straightforward, depending on how the HTML is written.
So, let’s just pick a random bit of the page which has some significant interlinear content:

The way to get a feel for what the markup looks like for this particular bit is to “inspect” the markup. We used to use a feature called “Viewing the source”, but “Inspecting the source” is a much better way to learn about how HTML works in practice. (Here’s a tutorial on how to do that: How to try Javascript now.)
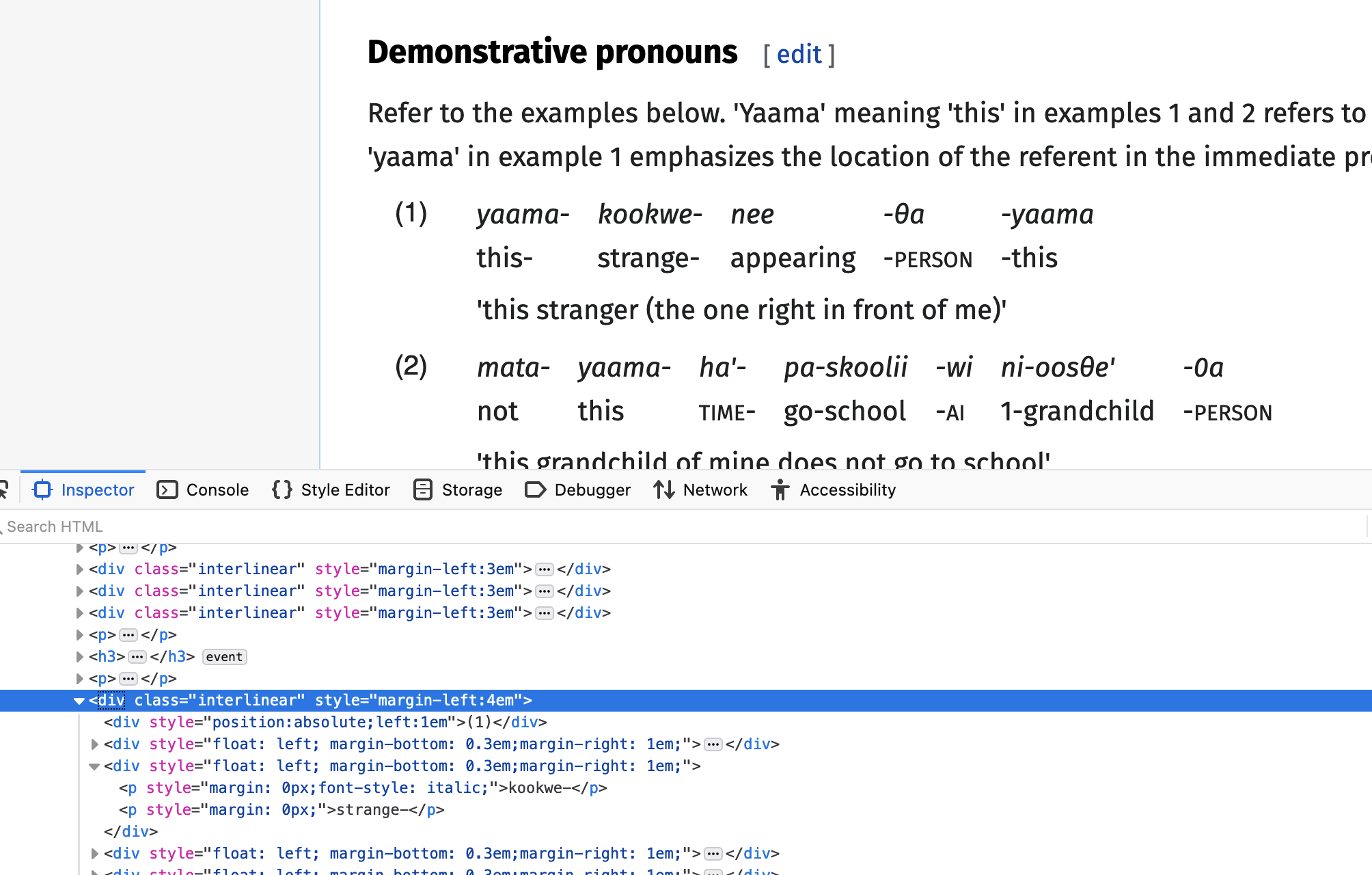
…But in this case, the markup is not super informative — you can see in the screenshot below that I’m inspecting example (1), but all the tags are just <div>s, without any classes to distinguish how the levels are set up. That’s going to be a royal pain to parse. So let’s… just not try to parse the HTML.
Wikipedia is made of wikitext
Oh boy. Wikitext. Love it, hate it… It will never go away because the biggest human-written anything ever, Wikipedia, is inextricably bound up in its complexities. wikitext is what you see when you edit an article. It is not… well, is fugly.
The pattern goes like this:
[graphviz]
strict digraph {
RANK=LR
Wikitext [shape=“polygon” style=“filled” ]
Parser [shape=“polygon” style=“filled” ]
HTML [shape=“polygon” style=“filled” ]
Wikitext → Parser → HTML
}
[/graphviz]
For most practical purposes, the Parser that converts Wikitext into HTML is a black box. It’s like an evolved organism. It’s bonkers. But the input to that parser is at least kind of understandable, if you can control your rage at how bewildering it is. So rather than inspecting the HTML, let’s see what the wikitext corresponding to the this stranger… example looks like. How do you do that? Well, you click edit. It’s easier to just edit a single section at a time, so we’ll click the edit link next to Demonstrative pronouns:

Which gets us:
===Demonstrative pronouns===
Refer to the examples below. 'Yaama' meaning 'this' in examples 1 and 2 refers to someone in front of the speaker. The repetition of 'yaama' in example 1 emphasizes the location of the referent in the immediate presence of the speaker.
{{interlinear|number=(1)|glossing=no abbr
|yaama- kookwe- nee -θa -yaama
|this- strange- appearing -PERSON -this
|'this stranger (the one right in front of me)'}}
{{interlinear|number=(2)|glossing=no abbr
|mata- yaama- ha'- pa-skoolii -wi ni-oosθe' -0a
|not this TIME- go-school -AI 1-grandchild -PERSON
|'this grandchild of mine does not go to school'}}
…etc…
Okay, that’s not too bonkers. At least we can see that there are chunks, and each interlinear begins and ends with double curly brackets. And the first line looks like this:
{{interlinear|number=(1)|glossing=no abbr
Okay, so it starts with {{interlinear, makes sense. In fact, this is what’s called a Template in Wikipedia parlance. If I understand correctly (correct me @sunny!), a template is basically a kind of syntax for indicating that the content “within” should be transformed before being handed to the parser. So it goes like this:
[graphviz]
strict digraph {
RANK=LR
WikitextWithTemplates [shape=“polygon” style=“filled” ]
Parser [shape=“polygon” style=“filled” ]
Wikitext [shape=“polygon” style=“filled” ]
Parser [shape=“polygon” style=“filled” ]
HTML [shape=“polygon” style=“filled” ]
WikitextWithTemplates → Parser → Wikitext → Parser → HTML
}
[/graphviz]
Or I mean, I dunno if that’s how it actually goes down, the point is, by the time you see the rendered HTML page, the template has been transformed.
The interlinear template
In point of fact, Wikipedia’s interlinear template is powerful. Real powerful. It can do an awful lot of stuff. Which means the “syntax” of the interlinear template gets a little hairy in its own right.
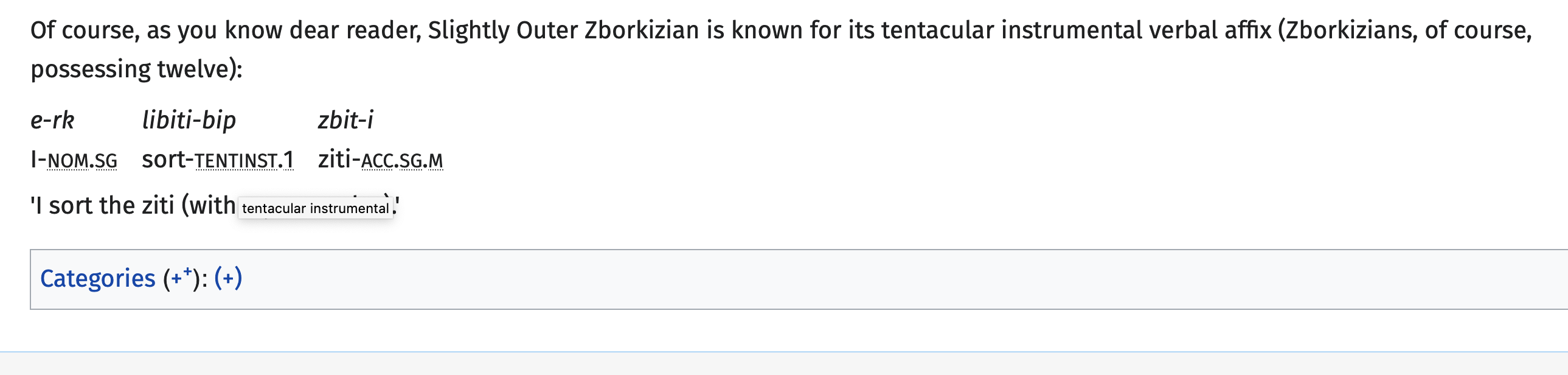
But just check out the documentation for the interlinear template:
Wouldja look at that. Pretty glosses! Small caps! You can add your own abbreviations. It lines up the words right! There is numbering! You can tweak stuff! It is, in short, pretty impressive.
But I don’t want all the other stuff, just the templates
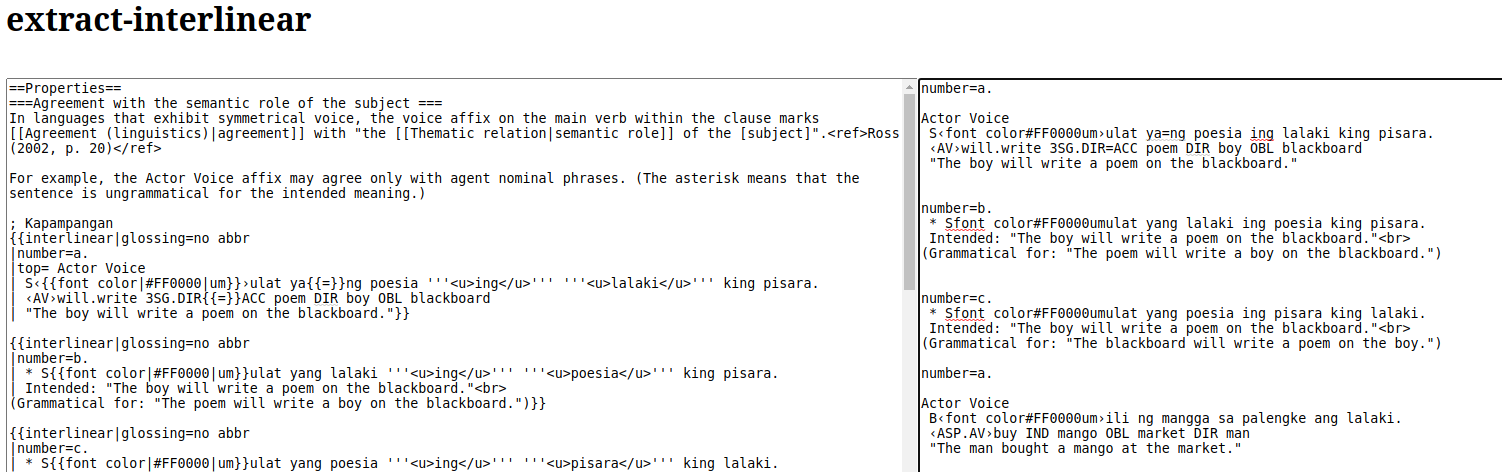
So, maybe we just parse the wikitext and slurp out all the instances of the {{interlinear}} template? Well, yeah. That’s what I did. I wrote a little app, and stuck it here:
So what you do is, you paste all the wikitext from a page into the left panel, and it tries to slurp out the interlinear templates and turn them into plain ’ol text in the right panel.

Like this:
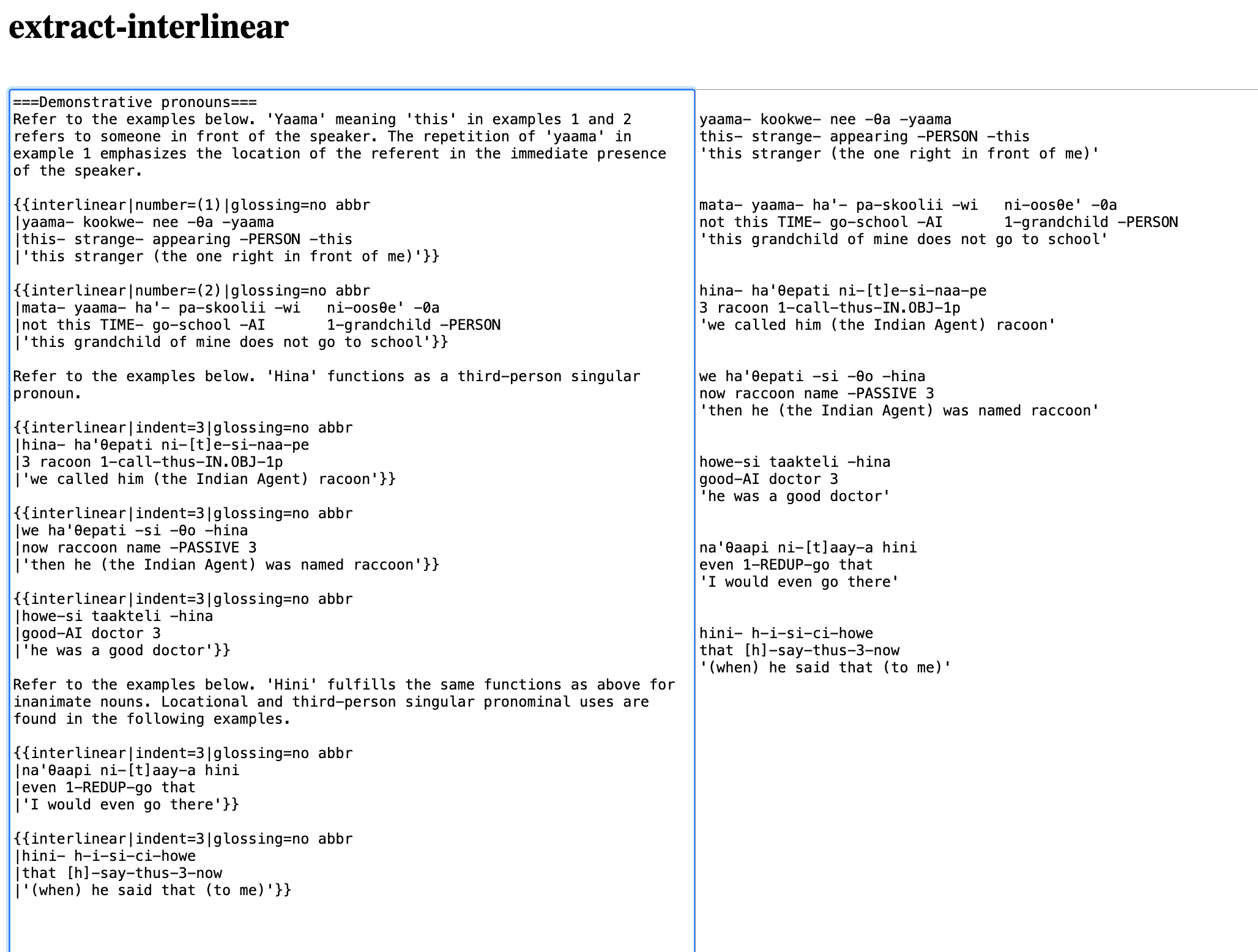
The “extraction” code tries to fix a few things, but I know for a fact that it does some bad things. But I’ve found that you have to start somewhere, and it’s better to try to make something
A clunky workflow (but some results)
So I ended up doing this… uh… 70 times.
- Search Wikipedia for pages using this query (see these docs)
- Open a bunch of tabs with all those articles

- Edit each one, cut and paste the content
- Paste it into the extractor
- Cut and paste the output into a file, save that.
Like I say, clunky. I’m a little obsessive about things like this, though, once I get started. And honestly I found it kind of fun, even just glancing at all those articles. The real fun should be trying to do something with them all, however.
How could it be better?
Well, I’m going to wrap it up for tonight, but there are lots of things that could be done:
- Try it on Wikipedias in other languages (Are template names in the
wikitextthe same on Wikipedias in every language?) - Put this stuff in a github repo instead of cramming it in articles here.
- Figure out how to download all the articles at once and run the extraction offline
So that’s really it.
When ideas for low-hanging fruit like this get into my head, I feel pretty much compelled to hack something together. I’m curious to know if anyone else finds this project interesting, or has any ideas about how to improve the workflow or make use of the output.
Gnight friends.