I thought this was interesting enough for a link:
It was posted in the languagelearning subreddit, where people talk about all kinds of language, but as usual it seems difficult to find materials in languages that aren’t “large”.
The idea is cool, though, and perhaps of interest. Basically you can search subtitles of videos by language, and, more importantly, by combination of language. So for instance, here is a search for videos with subtitles in Portuguese and English:
https://filmot.com/captionLanguageSearch?channelID=&captionLanguages=en%20pt%20&capLangExactMatch=1&
I randomly added the title query “obrigada”, just to get fewer results:
I spend a big chunk of my day messing with linguistic data in different contexts, and being able to find “parallel text” from YouTube with this search engine was quite fun. I tried finding content in Fulfulde (called Fulah on YouTube) and a few other less economically dominant languages, but I didn’t have much success. So I tried Portuguese, because, well, there were tons of results.
In this rest of this post, I’m going to walk through the steps I took to extract the data from YouTube and turn it into a “JSON in the Middle” kind of representation that is a more useful starting point ( I think, anyway) for further documentation work. I’m not entirely sure that it will seem terribly useful to any readers here, but maybe. Also, I find it fun. ![]()
Non-programmer summary:
YouTube videos have subtitle data associated with them. If you can find a video with the pair of languages you want, then it might be worth extracting that data and putting it into a linguist-friendly format. In this post I show the steps that I took to merge Portuguese & English subtitles into a time-aligned parallel text
JSONformat.
The most common tool I use is the “developer tools” — the thing you see at the bottom of the screenshot below. In this post I introduce the Network tab, which lets you see the requests your browser is making as it loads a page. The nature of these requests deserves a workshop of its own, but since I was doing this anyway out of my own interest I thought I’d document the steps.
So YouTube has a rather weird JSON format called “timed text”. You can get at it via the console, here’s how I did it. When you load the video, open the console and go to the Network tab. Then, change the subtitle language option. You should see a line pop up in the network log, like this:
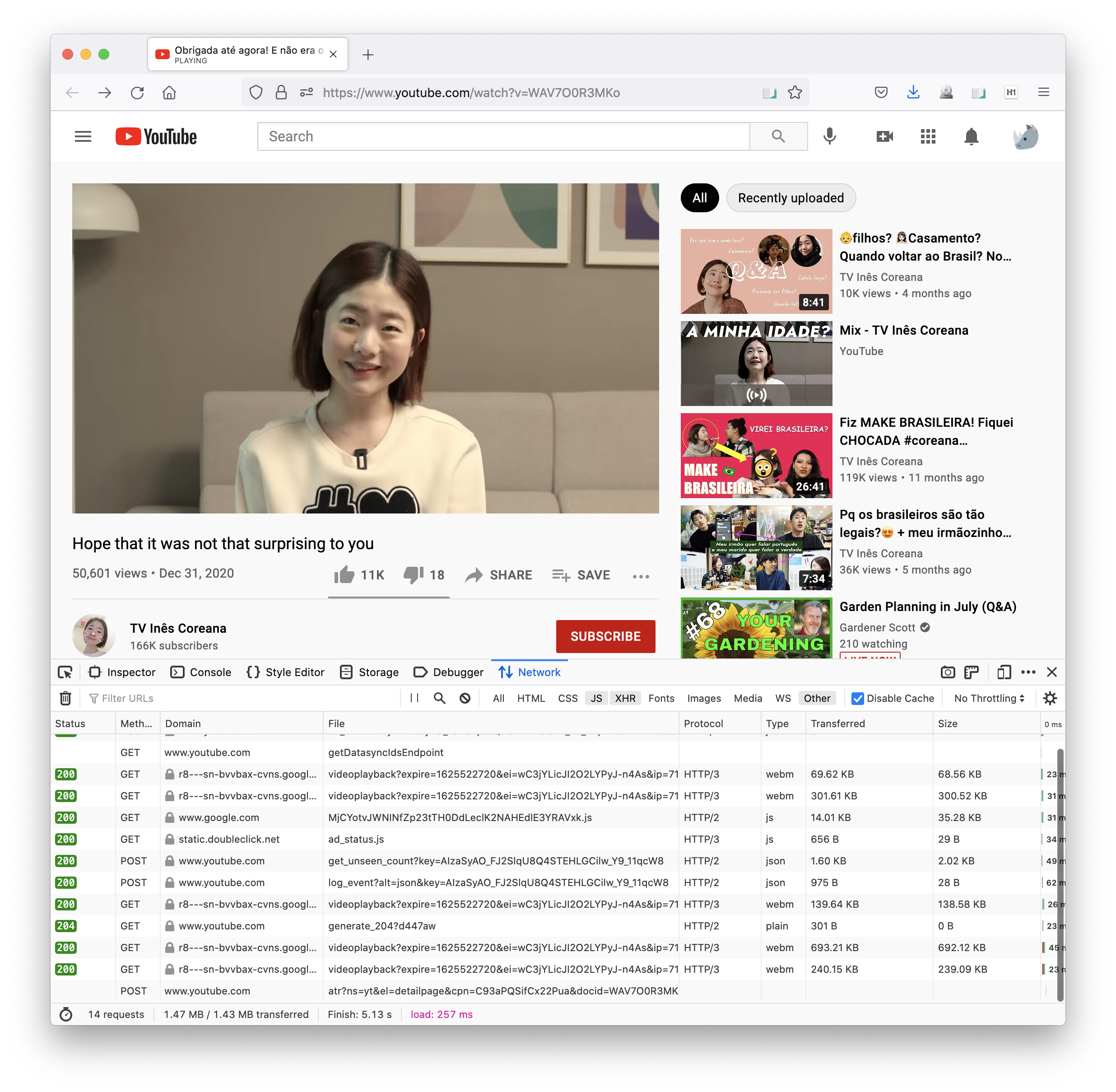
All those lines at the bottom are each of the requests that the browser is making as the content of the page is loaded — the HTML, images, the video itself, etc. We’re looking for the files that happen to contain the subtitles. So, you can search in the box where it says “Filter URLs”. After some poking about I figured out that the request for the actual content of the subtitles includes the string timedtext,
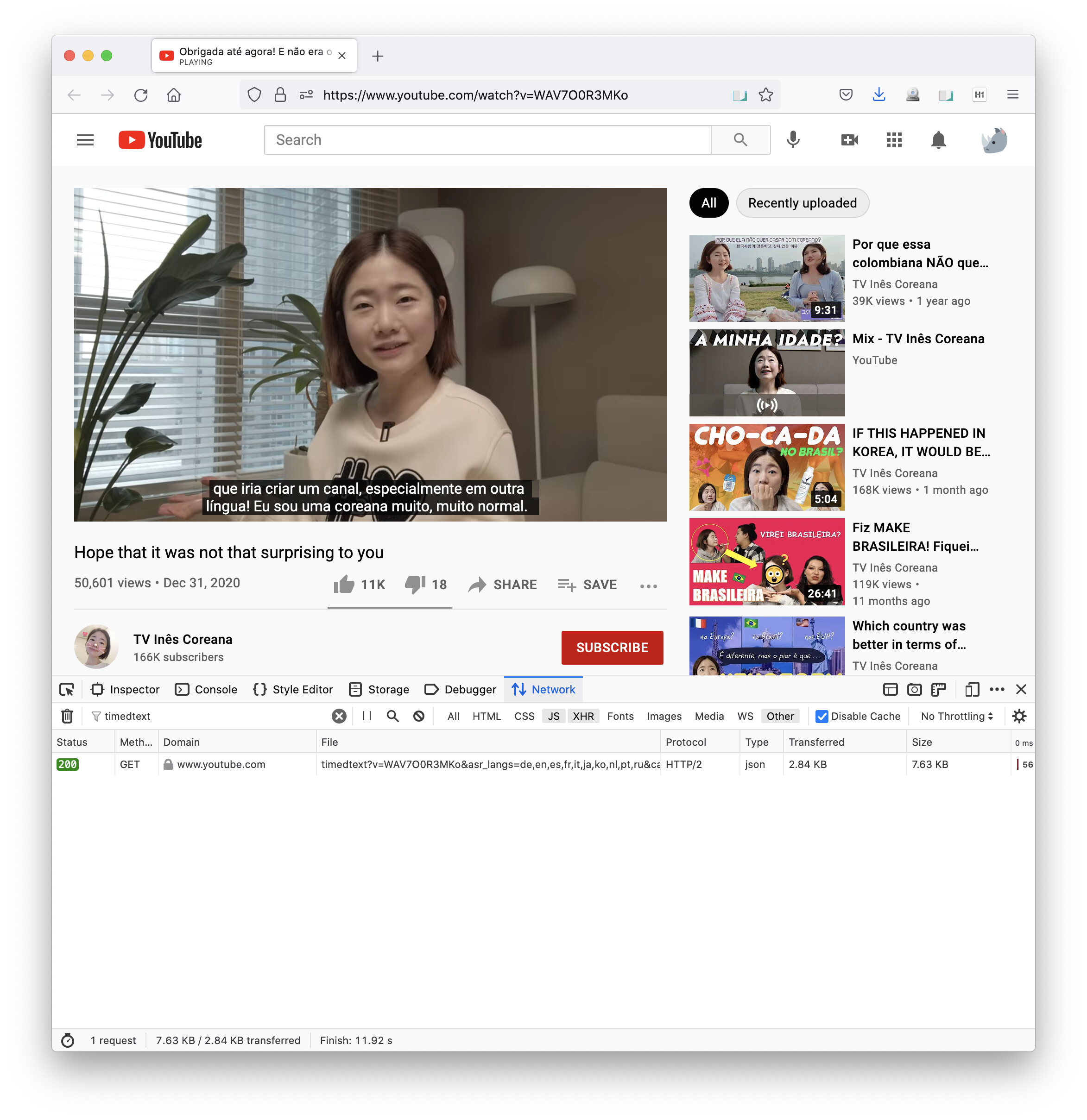
You can see the bonkers URL right here:
Rather than mess with that, you can just click the URL, and a new tab will open, finally, with the JSON content of whichever language you chose in the options:
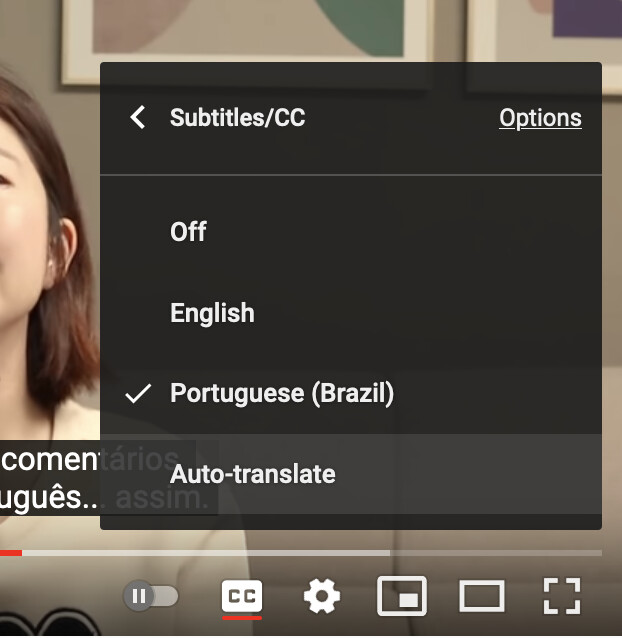
If you change the settings, a new URL will pop up, and you can get the other language’s file.
So, at long last, we end up with the data in the form of JSON. Here’s a bit of the Portuguese file:
{
"wireMagic": "pb3",
"pens": [ {
} ],
"wsWinStyles": [ {
} ],
"wpWinPositions": [ {
} ],
"events": [ {
"tStartMs": 2220,
"dDurationMs": 3180,
"segs": [ {
"utf8": "Oi, gente, tudo bem com vocês? Espero que sim!"
} ]
}, {
"tStartMs": 5400,
"dDurationMs": 4410,
"segs": [ {
"utf8": "Se vocês forem novos aqui, sou \na Inês (meu nome em português), "
} ]
}, {
"tStartMs": 9810,
"dDurationMs": 7560,
"segs": [ {
"utf8": "coreana. O meu canal é sobre a cultura e a beleza \ncoreanas, diferenças entre o Brasil e a Coreia."
} ]
}
And here’s a bit of the English one (I think this is human-translated, since it’s not labeled as auto-generated in the language popup, but I’m not sure. Turing test fail):
{
"wireMagic": "pb3",
"pens": [ {
} ],
"wsWinStyles": [ {
} ],
"wpWinPositions": [ {
} ],
"events": [ {
"tStartMs": 2220,
"dDurationMs": 3180,
"segs": [ {
"utf8": "Hi, guys, how are you? I hope so!"
} ]
}, {
"tStartMs": 5400,
"dDurationMs": 4410,
"segs": [ {
"utf8": "If you're new here, I'm Inês (my name in Portuguese),"
} ]
}, {
"tStartMs": 9810,
"dDurationMs": 7560,
"segs": [ {
"utf8": "Korean. My channel is about Korean culture and beauty, differences between Brazil and Korea."
} ]
}
]
}
Some of this stuff is… whatever. But the (weirdly named) events attribute contains an array of objects which contain the info we need: a start time called tStartMS (presumably “time start milliseconds”), dDurationMs (duration in milliseconds), and finally segs (“segments”, presumably), which has a rather odd internal structure of its own array with values labeled by encoding (utf8… how odd).
{
"tStartMs": 2220,
"dDurationMs": 3180,
"segs": [ {
"utf8": "Hi, guys, how are you? I hope so!"
}
This is what we’re after. So, if you take the Portuguese and the English, the time stamps are the same, and you can line them up, finally getting a simpler data structure which unifies the two files with labels that should be reasonably familiar to a documentary linguist. Here’s what the final output looks like after some rearrangement:
{
"metadata": {
"title": "Obrigada até agora! E não era o segredo, mas.. tá na hora de falar. - YouTube",
"source": "YouTube",
"speaker": "Inês Coreana",
"language": "Brazilian Portuguese",
"translation": "English",
"url": "https://www.youtube.com/watch?v=WAV7O0R3MKo",
"notes": [
"The content of this file was derived from the subtitle content of the following two links: https://www.youtube.com/api/timedtext?v=WAV7O0R3MKo&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt%2Cxctw&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1625525288&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=AC3A59309CB283203B0AA30D2FBEFD64BF7E4F21.0B1652875282343FA5D9F6B92AAD6041A56A8A3A&key=yt8&lang=en&fmt=json3&xorb=2&xobt=3&xovt=3 and https://www.youtube.com/api/timedtext?v=WAV7O0R3MKo&asr_langs=de%2Cen%2Ces%2Cfr%2Cit%2Cja%2Cko%2Cnl%2Cpt%2Cru&caps=asr&exp=xftt%2Cxctw&xorp=true&xoaf=5&hl=en&ip=0.0.0.0&ipbits=0&expire=1625525288&sparams=ip%2Cipbits%2Cexpire%2Cv%2Casr_langs%2Ccaps%2Cexp%2Cxorp%2Cxoaf&signature=AC3A59309CB283203B0AA30D2FBEFD64BF7E4F21.0B1652875282343FA5D9F6B92AAD6041A56A8A3A&key=yt8&lang=pt-BR&fmt=json3&xorb=2&xobt=3&xovt=3"
]
},
"sentences": [
{
"translation": "Hi, guys, how are you? I hope so!",
"links": [
{
"type": "video",
"start": 2.22,
"end": 5.4
}
],
"transcription": "Oi, gente, tudo bem com vocês? Espero que sim!"
},
{
"translation": "If you're new here, I'm Inês (my name in Portuguese),",
"links": [
{
"type": "video",
"start": 5.4,
"end": 9.81
}
],
"transcription": "Se vocês forem novos aqui, sou \na Inês (meu nome em português), "
},
{
"translation": "Korean. My channel is about Korean culture and beauty, differences between Brazil and Korea.",
"links": [
{
"type": "video",
"start": 9.81,
"end": 17.37
}
],
"transcription": "coreana. O meu canal é sobre a cultura e a beleza \ncoreanas, diferenças entre o Brasil e a Coreia."
}
]
}
I think this is a reasonable “archival” representation of the subtitle content of this video as parallel text — note that there isn’t any morphological analysis, or even tokenization. But that could be added later.
And I guess I might as well share the bit of Javascript I used to merge the two files:
// `en` points at the data from the English file
// `pt` points at the Portuguese
let sentences = en.events.map((e,i) =>
({
translation: e.segs[0].utf8,
transcription: pt.events[i].segs[0].utf8,
links: [
{
type: 'video',
start: e.tStartMs/ 1000,
end: (e.tStartMs + e.dDurationMs) / 1000}
],
})
)
let metadata = {
"title": "Obrigada até agora! E não era o segredo, mas.. tá na hora de falar. - YouTube",
"source": "YouTube",
"speaker": "Inês Coreana",
"url": "https://www.youtube.com/watch?v=WAV7O0R3MKo"
}
let text = {metadata, sentences}
Now, that text object at the end could be saved in a file and rendered in useful ways.