In the old days, before Unicode, people did some crazy stuff to try to get complex text to appear on the web.
I have been studying a language called Pali, and this website contains a text called the Dhammapada. The text is traditionallly divided into numbered, 4- or 8-line stanzas called gathas, and each of those gets its on page on the site.
So Gatha 1 one looks like this:
http://buddhism.lib.ntu.edu.tw/BDLM/lesson/pali/reading/gatha1.htm
There’s a ton of syntactic, morphological and lexical information in these pages, but there is a serious problem: the content is weirdly encoded. In this post I would like to explain what that problem was, and how a rather kooky work-around called a “bookmarklet” can be used to help. Creating bookmarklets is a bit of a hassle, even if you know Javascript, but nonetheless I think discussing what bookmarklets do could potentially be enlightening about some aspects of the web we all use all day.
Pali
Pali is a pretty neat language for several reasons, but I’m going to try to stay on topic! For the purposes of this discussion, all we need to keep in mind is that there is a Romanized orthography that is widely used (and used on the site linked above), and that that orthography has several diacritics. Vowels can be marked with a macron (ā, ī, ū), and like many Indo-Aryan languages, retroflex consonants are written with a dot below — ḍ, ṭ, etc. (and there are a few more; you can see a full table here).
Anyway, the text at Gatha 1 looks fine:
Manasā ce paduṭṭhena
Lovely little diacritics.
But things get complicated later on. For instance, the second line of Gatha 100 appears like this:
ekaj atthapadaj seyyo yaj sutva upasammati
This is all kinds of not right. Pali doesn’t have final j, ever. What gives?
It’s in the HTML
I right-clicked (command-clicked, actually, in my case, as I use a Mac) and then ran inspect element on that second line (try it on the page!) and boy howdy, did I see some… special HTML.
If you do any work in HTML you will know that this is… gross. <center> is obsolete, as is, emphatically, <font>. So that’s the first clue we’re dealing with old stuff here.
It’s not hard to find other versions of this text (it’s quite famous), and then we can compare what we have with what we expect.
So a correct rendering of the line is:
Ekaṃ atthapadaṃ seyyo, yaṃ sutvā upasammati.
So, aligning the two:
ekaj atthapadaj seyyo yaj sutva upasammati
ekaṃ atthapadaṃ seyyo, yaṃ sutvā upasammati.
So the «j» corresponds to an … «ṃ»?
And the «a» corresponds to an … «ā»??
Waaait a second… both «a» and «ā» exist in Pali!
In technical terms, WTF?
I did some digging and figured out the whole “transliteration” table:
| crazy | not crazy |
|---|---|
| a | ā |
| j | ṃ |
| n | ṇ |
| v | ṅ |
| i | ī |
| b | ñ |
| t | ṭ |
How in the sam hell they came up with that scheme I do not know.
So fix it dear Henry
The information in these pages is so useful to me that I was motivated to figure out how to fix it, somehow. What were my options?
- I could download every page from the site, and write a program to fix it so I would have a local mirror.
- I could email the people who run the site and ask them to fix it. I’m much to impatient for that.
- I could try to fix in when I’m on the site, using Javascript.
Naturally I went with option 3.
Man, this post is getting long.
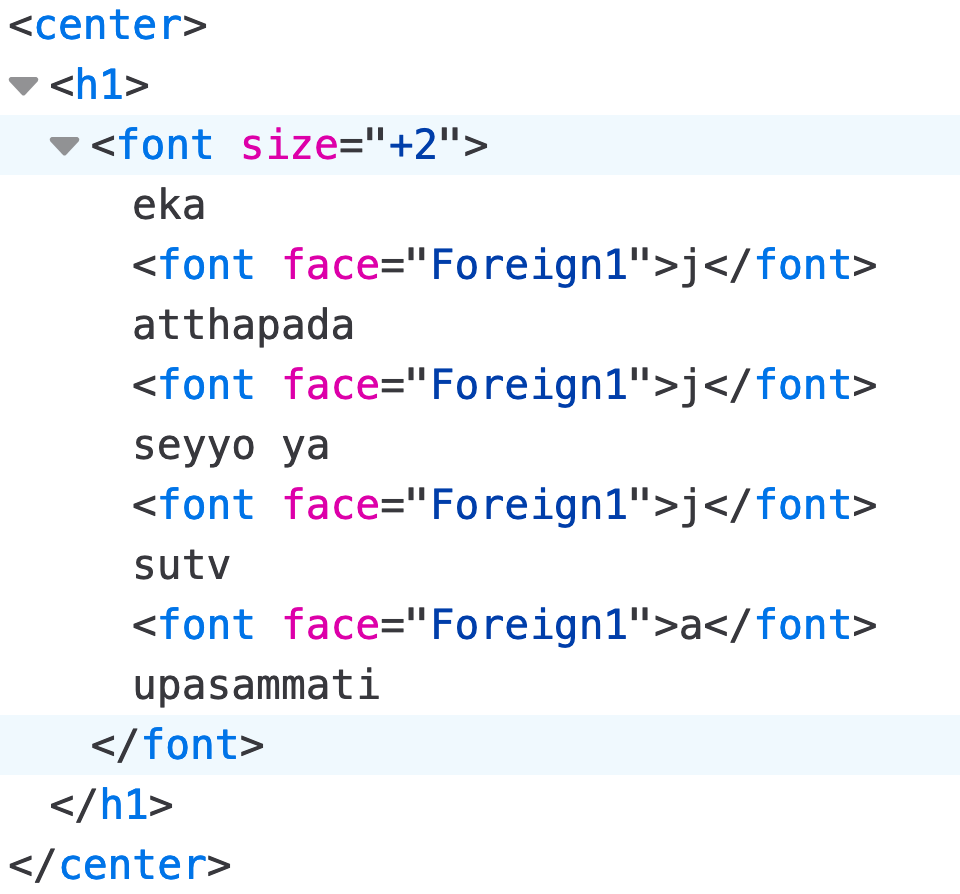
So taking a closer look at the HTML, we see this:
<center>
<h1>
<font size="+2">eka<font face="Foreign1">j</font> atthapada<font face="Foreign1">j</font>
seyyo ya<font face="Foreign1">j</font> sutv<font face="Foreign1">a</font>
upasammati</font></h1></center>
ekaj atthapadaj seyyo yaj sutva upasammati
So let’s forget abotu the <center>, <h1>, and <font size="+2"> (blech!) for a minute, and focus on the <font face="Foreign1"> bits. In particular, compare these two words: yaṃ and sutvā. The first one has a short «a», and the second has a long ā.
But look at the HTML for those two words:
ya<font face="Foreign1">j</font>
sutv<font face="Foreign1">a</font>
The mystery is solved
This crazy HTML is using an equally crazy font where letters pretend to be other letters!
![]()
That’s right kids, for this page to “look” right, you have the font known as Foreign1 on your system (you have to install it just for this site!). Whatever that font is — there’s no way to know from just reading the actual page.
And in that crazy font (which I very much do not want anywhere near my system!), any instance of a letter from the “crazy” column is told to render as its equivalent in the “non crazy” column. Inside of <font face=Foreign1>, «a» means «ā». Anywhere else, «a» is «a».
This means that if you have this crazy font, in order to search for the word yaṃ, you have to type yaj in your search box.
This is not the way to enlightenment.
Henry you have not fixed it yet
Phew. So now we need to fix it.
I’m running out of steam so I’m not going run through the code I used to fix it in too much detail, but in general terms it goes like this:
- Store the crazy/notcrazy correspondences
- Find all the
<font face=Foreign1>tags - Replace every crazy character inside those tags with its corresponding not crazy character.
Done.
Here’s one way to write that in Javascript:
let fix = () => {
// (1) crazy/not crazy correspondences
let fixes = {
"a": "ā",
"j": "ṃ",
"n": "ṇ",
"v": "ṅ",
"i": "ī",
"b": "ñ",
"t": "ṭ"
}
// (2) the offending tags
let fontTags = document.querySelectorAll('font[face=Foreign1]')
// (3) the complicated bit that carries out the substitution
fontTags.forEach(fontTag => {
let content = fontTag.textContent.trim()
let crazies = content.split``
fontTag.outerHTML = crazies
.map(crazy => fixes[crazy] ? fixes[crazy] : crazy)
.join("")
})
}
// (4) run the function.
So if you open the console and paste in that code and run it on a page like Gatha 100, you will see the crazy go away, presto-change-o.
I am easily amused.
One more thing: a bookmarklet
Well, great. But cutting and pasting code, opening the console, and then running it is an awful lot of work. If I’m (hah!) going to read all 423 of these things, do I have to do that 423 times?
That would suck.
Well, we can at least get it down to one-click-per-page using a weird thing called a bookmarklet. Again, there are some weird aspects (even for a Javascript programmer) that I won’t go into here about how one converts random JS code into a bookmarklet, but the basic idea is that you’re creating a link (an <a>) whose value is not a URL, but some code.
One way to create a bookmarklet is just to drag then from a page into your bookmarks toolbar on your browser (here’s a venerable collection (some of which no longer work, but you get the idea)).
So I set one of those up and stuck it on the web here:
https://ruphus.com/fix-ntu.html
You can drag that to your bookmarklets and go to a page like this one, and then click it. And remember not to get too angry at your computer.
Does this have anything to do with language documentation?
Well, sort of. In cases where you are working with some web resource a lot, a bookmarklet can sometimes save you tons of time or at least make your life easier. For instance, the UCLA Phonetics Archive has an astounding amount of content. But there are some features that are super annoying: one is that all the audio files are only linked, not shown as <audio> tags. This means that they cannot be played while you are browsing the page.
That sucks.
So, you could write a thing that creates an inline play button, like this:
document.querySelectorAll('a[href$=wav]')
.forEach(a => {
a.innerHTML = `▶️ PLAY`
a.addEventListener('click', e => {
// don’t follow the link
e.preventDefault()
// create an audio tag
let audio = document.createElement('audio')
audio.src = a.href
audio.controls = true
a.after(audio)
})
})
A bookmarklet that carries out that step like that could conceivably be useful on a page with a ton of recordings, like this one on Zulu.
Here’s a bookmarklet you can try if so inclined: