Trying this “reply as topic” functionality. You can too: when you reply to another post, choose the chain icon and click “New Topic”. This is useful for spinning off more detailed conversations from a more “general” topic like “What’s your project?”
So this is a very cool corpus. Here’s how I understand your workflow, @Hilaria:
Inputs
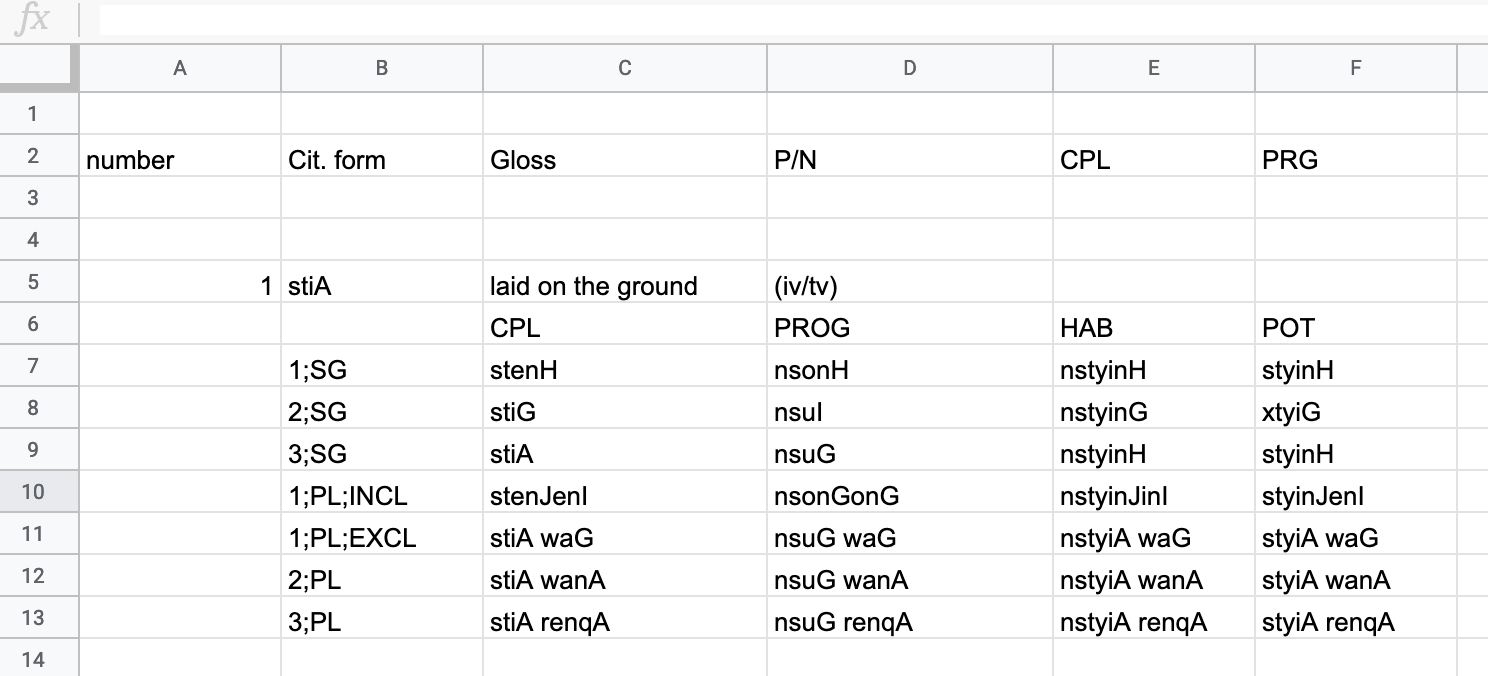
You’re starting with a spreadsheet that represents verb paradigms, one of which looks like this:
There are about 200 of these in the current state of your corpus.
You expect to continue editing this.
Outputs
These paradigms should be added to Wiktionary, as similar tables?
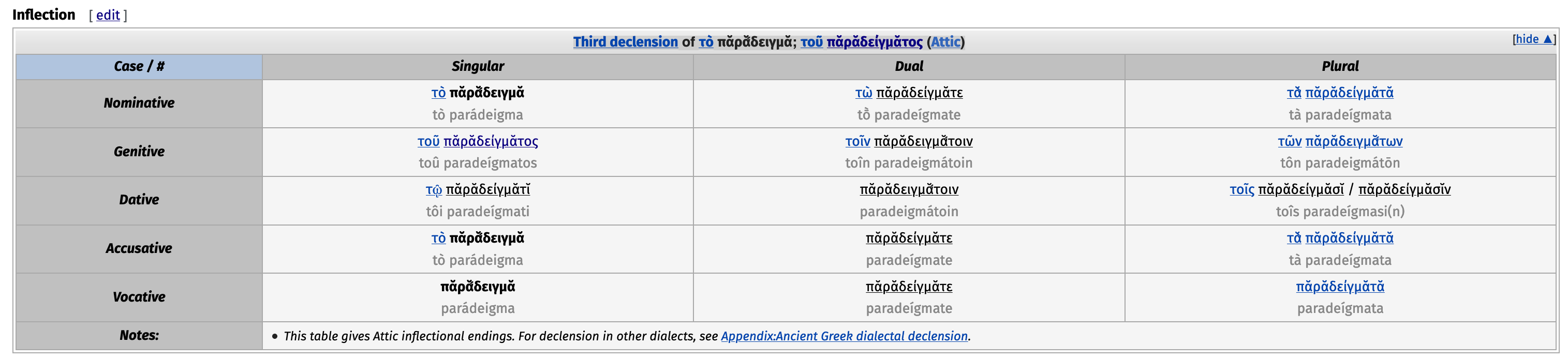
From what I can tell, Wiktionary uses a pretty hairy syntax for generating paradigmatic tables, although the final product is quite pretty. Here, for instance, is a paradigm for the declination of the Ancient Greek word παράδειγμα ‘paradigm’ (ha, ha):
I’m not sure I have the bandwidth to learn the paradigm generation syntax on Wiktionary just now, but I still might be able to help… let me get back to you after thinking about it a little.
Awesome, sounds exciting! the Greek example is great and I would like to add the sound files as well. Maybe we could write an article from the experience. Perhaps others can join the effort.
Hi !
Can I ask why it has to be Wiktionary over some other platform?
I’m interested to hear about it because Carmen and I have been working on verb paradigms in her variety of Mixtec and we had started to think how these will best be displayed online in the future. (And we also store them in a spreadsheet with separate sound files.)
Hi @Sandra and @Hilaria, I find this conversation interesting. I think we could break the project down into several parts: several steps for getting from the paradigms as they are now to a Wiktionary interface.
But it’s worth noting that among the several steps may be some reusable steps that may be independently useful.
The way I have come to think about data and applications for documentation is kind of like a recipe: there are ingredients (inputs) and dishes (outputs). Some recipes (say, for gravy) have outputs that are inputs to other recipes (like mashed potatoes and gravy).
Something like going from a paradigm corpus all the way up to a user-friendly Wiktionary interface (or better, a system that can repeatedly build such interfaces) is a long and winding road. The first step, I think, is to try to map out the set of steps.
It may well be that one of the steps on the road (say, editing or searching verbal paradigms in general) could be of use and interest to both the Chatino-language community and other research goals such as Sandra’s verb paradigm research.
I have to crash unfortunately but I hope we can continue talking about this. It’s exactly the kind of thing that I hope to foster around here: by discussing what we’re up to, we can find ways to collaborate, and that should remain true, especially true, when there is only partial overlap in ultimate goals. It’s about breaking down big (and often unique) projects into small pieces, implementing those pieces in generic ways, and then using the generic bits as building blocks in other big, unique projects.
I’m not super familiar with Wiktionary, but I have done a fair amount of work on Wikipedia. They have a pretty icky syntax for editing content, but what could probably be done would be to create a tool that takes your input information and generates a Wiktionary table. Then you could paste that into the article you want to edit.
Hi folks, just wanted to let you know that I moved the discussion about this from What are your projects and project ideas? to this dedicated page. Things are a little out of order now, sorry!
Wow congrats! This is so cool. I wonder if you and @lgessler (and perhaps Aryaman, if he’s interested in joining!) might be willing to tell us a little about the process you went through to make this happen?
Hi! Sorry (perhaps ironically since I’m supposed to be in CS) it took a bit to figure out how to use this forum haha. I’ll explain a bit on how the whole upload was done.
I’m not too sure about the data collection aspect since Hilaria managed all of that of course, but once I had the spreadsheet with all the verbs with their meanings and conjugation paradigms, it was not difficult at all to upload.
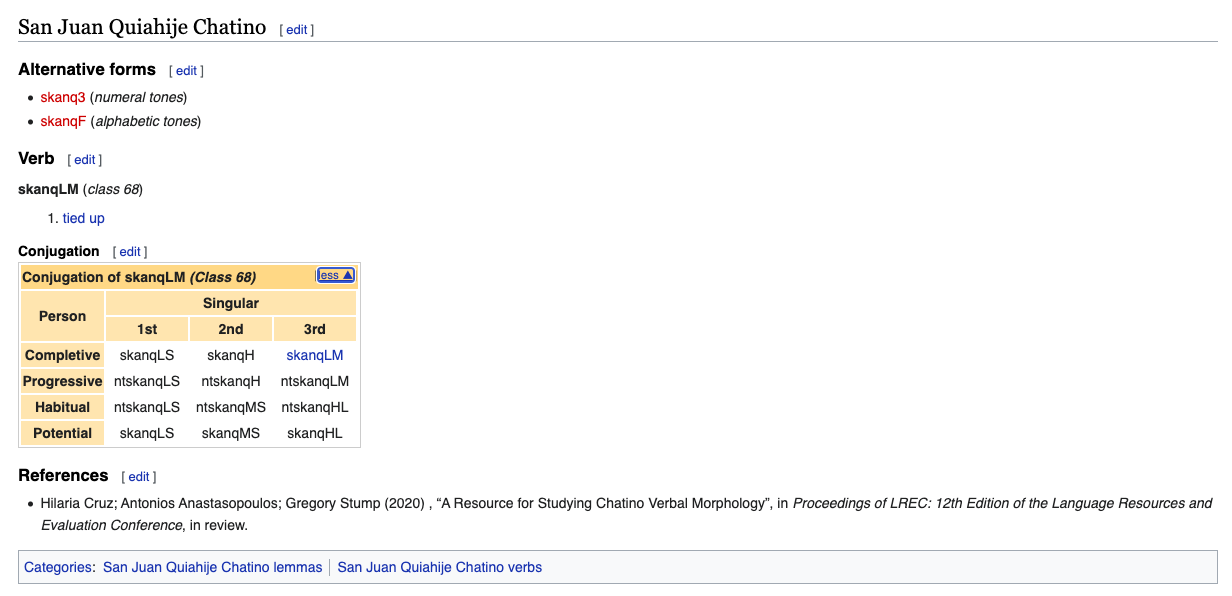
The first step was ensuring there was infrastructure for San Juan Quiahije Chatino on Wiktionary.
Unfortunately, San Juan Quiahije Chatino does not have its own ISO code (it’s subsumed under ctp “Western Highland Chatino”) so I created a new code ctp-san for it. I have admin rights as a longtime editor on Wiktionary (I mainly manage a variety of Indo-Aryan languages, especially my native Hindi) so I have rights to create new language codes and edit protected backend pages.
I made a special headword-line template for SJQ Chatino verbs. Different languages encode different information in the headword; for SJQ Chatino, this would be the verb class.
I made a conjugation template that has slots for the verb paradigm of Chatino that was recorded in the corpus.
Templates are basically reusable formats that can be put on lots of pages. I pass some variables to the template (e.g. verb class, different verb forms) and the Mediawiki engine will render the template filling in the slots that I have provided. This way, we don’t need to worry about all the HTML code for making a nice conjugation table on every SJQ Chatino verb entry, we just do it once and reuse.
After the infrastructure was there, I wrote a short (and mess, sorry!) script in Python that would:
parse the entire spreadsheet with all the lemmas, verb classes, meanings, and verb forms
generate the proper formatting for a Wiktionary entry using all that data, on top of the infrastructure that was put in place earlier
Wiktionary has very strict formatting guidelines that take some experience to understand.
I realized partway that some verbs shared identical forms put different meanings and paradigms, so I also had to handle that and ensure the previous entry wouldn’t be overwritten
This also involved generating forms in the two other orthographies for tone that are used by SJQ Chatino.
upload the new entries onto Wiktionary using the pywikibot library
(as a note, this required the use of a bot which had to be approved in a vote by the Wiktionary community; unapproved bots can’t be filtered from the Recent changes list which makes checking for vandalism by admins difficult)
The whole process took a few weeks, but that was with my own work in the way at times.
You can see all the entries that were uploaded here.
I’m interested in making a Python library that can handle all of the Wiktionary formatting guidelines, since that seems to be the major hurdle to uploading this kind of information. Oh, and if anyone is interested in uploading language data to Wiktionary, I would be happy to help out.