Recently, I and @lgessler worked with @Hilaria to upload her corpus data and audio recordings for the variety of Chatino from San Juan Quiahije onto Wiktionary (this post). After that, I did another project to upload Henrik Liljegren’s dictionary of the Palula language of Pakistan (~3k entries) onto Wiktionary.
We’ve since realised that uploading a lexicon to Wiktionary is a hassle for those who do not know the strict formatting standards. So, we have been working on a Python module that can handle all the formatting for you as long as you can parse your data into a structured format!
To rehash for those who are unfamiliar, I am an admin on the English Wiktionary, which serves as a collaborative multilingual dictionary built on the model of Wikipedia. I’m interested in making our language documentation data more accessible to the public through Wiktionary.
Presenting: the Wiktionary Data Preparer!
WDP is a module for parsing structured data from a lexicon and preparing it for upload to Wiktionary. Most of the code was written by @lgessler with minor direction and edits by me. We’ve linked to the GitHub repo above so you can see the code for yourself.
In WDP, we treat each entry in a lexicon as a Word object. WDP Words have convenient methods for adding the kind of information that makes up a Wiktionary entry. Here’s a minimal example:
Expand for code!
from wdp import Word, format_entries, export_words
# use the Word class to represent our words
apple = Word("apple")
apple.add_pronunciation("/ˈæp.əl/", notation="IPA")
apple.add_definition("A common, round fruit", "Noun")
apple.add_definition("A tree of the genus Malus", "Noun")
apple.set_etymology("Old English æppel < Proto-Germanic *ap(a)laz < PIE *ab(e)l-")
# put all our words in a list
wdp_words = [apple, ...]
# Generate Wiktionary markup from our entries
formatted_entries = format_entries(wdp_words, "en", "English")
# Perform the upload
from wdp.upload import upload_formatted_entries
upload_formatted_entries(formatted_entries, "English")
Here’s what that looks like once uploaded (that last line of code does that):

You can read the docs for WDP and go ahead and download it to test! It’s on pip:
$ pip install wdp
Testing WDP
I’ve been doing language documentation of Kholosi since last semester. Kholosi is a marginalised Indo-Aryan language of Iran, with speakers mainly in two villages (Kholos and Gotaw) and many more distributed throughout Iran. Speakers number in the thousands. Currently working on a submission to JIPA for that ![]() (And as an aside, you can see some of my data here.)
(And as an aside, you can see some of my data here.)
I collected a lexicon of ~400 words in the course of my elicitation. This was in Google Sheets, and I wanted to upload it to Wiktionary. So of course, I thought to use WDP as a demonstration.
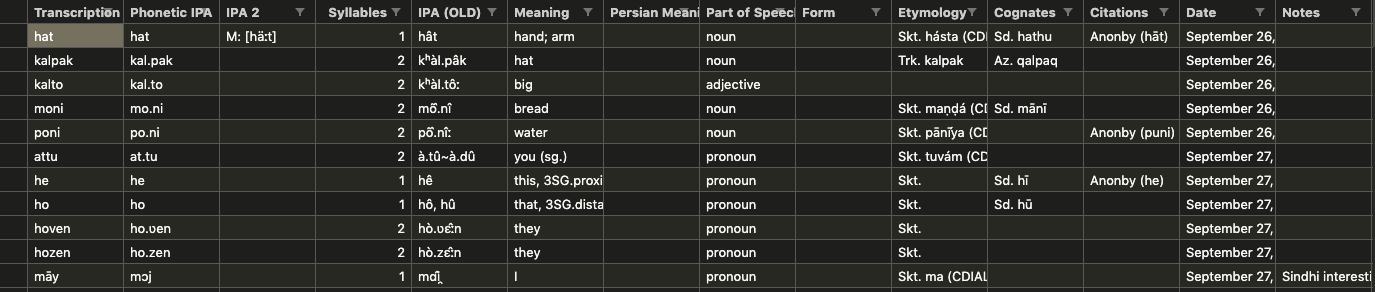
The CSV lexicon.
After exporting the lexicon to an easily machine-readable CSV file, I wrote a short Python script that parses my data. You can see that code here! In only about ~100 lines (took just last night to write) I was ready to upload data that would take days to manually add to Wiktionary. The upload itself took only a minute.
For testing purposes, I only uploaded to my userspace on Wiktionary, not the main Wiktionary space. You can see the results in User:AryamanBot’s edit history!
The only extra step needed was a user-config.py in the same directory. The Python interface for wikis (pywikibot) has some special guidelines for those; you can see the code for that here. You also need an approved (through a public vote) bot account on Wiktionary if you want to do it yourself. The easier way is to export a zip using wdp.export_words() and send it to one of us to run the upload.
Future steps
There are still many features to add to WDP. Some of what we have in mind:
- Automatic linking of English words in definition lines using a lemmatiser.
- Handling of semantic relations (synonyms/antonyms/etc.).
- Better support for inflectional data in the form of pretty tables.
- Code-free upload from FLEx Dictionary XML or other popular formats.
So, what do you think? Feel free to suggest any useful features or other thoughts! And we’re happy to collaborate with you if you want to contribute to the codebase, or have a lexicon to upload to Wiktionary ![]()
 . Words get nodes, so things can wrap correctly.
. Words get nodes, so things can wrap correctly. )
)