Right, so, ChatGPT.
(Pretty sure some people just skipped over this topic, it’s everywhere, I know!)
I have to admit that my initial reaction to ChatGPT’s ability to write Javascript/HTML/CSS applications was kind of… well…
Here’s a repo containing the source code from this example if you are interested:
https://github.com/amundo/chatgpt-experiments
Some of it was written by me and some of it was written by… the AI…
![]()
Searching for emojis
It is kind of amazing that it can take a plaintext description of an application and turn it into functioning, commented code. So for instance, this request worked pretty well:
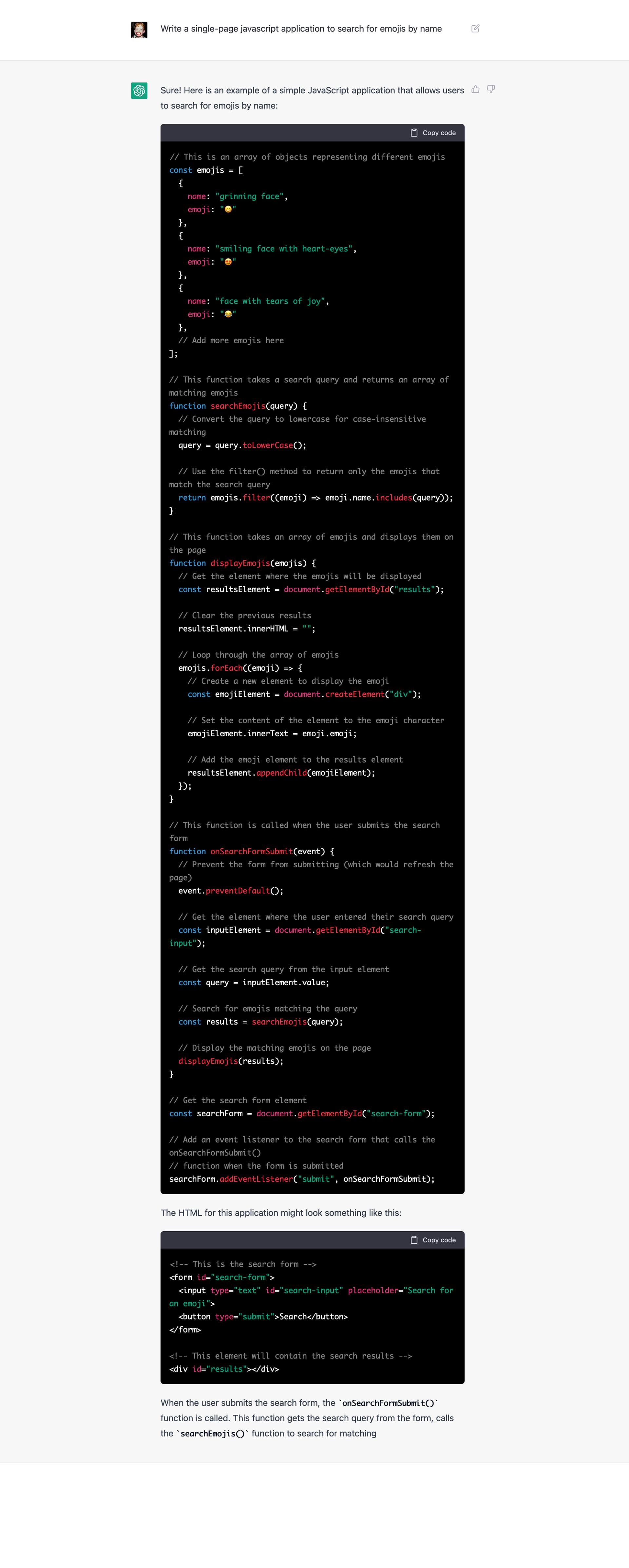
I realize that this task hardly qualifies as “documentary linguistics”, but the pattern of querying an array and rendering the output is one that comes up again and again — searching wordlists or texts, for instance. I think it’s a good learning task, so I used it as an example in the class I’m teaching at Yale (which is almost ending ![]() ).
).
The sample data is almost exactly the same structure as what I used as a demo in my current class for this task. And the code does… well, exactly what our demo did in class.
It’s worth noting that the output doesn’t really take “end users” into account very much, because it doesn’t have much in the way of help text (well, I guess there is the Search for an emoji… placeholder attribute). Still, though, kind of nuts, right?
You can try it yourself here:
https://ruphus.com/chatgpt-experiments/emojisearch/emojisearch.html
All I added was the skeleton HTML page to put the generated form inside.
Finding minimal pairs
This example also seemed pretty ![]() at first, but it took some work to realize 1) what it’s trying to do and 2) the fact that it doesn’t actually work right.
at first, but it took some work to realize 1) what it’s trying to do and 2) the fact that it doesn’t actually work right.

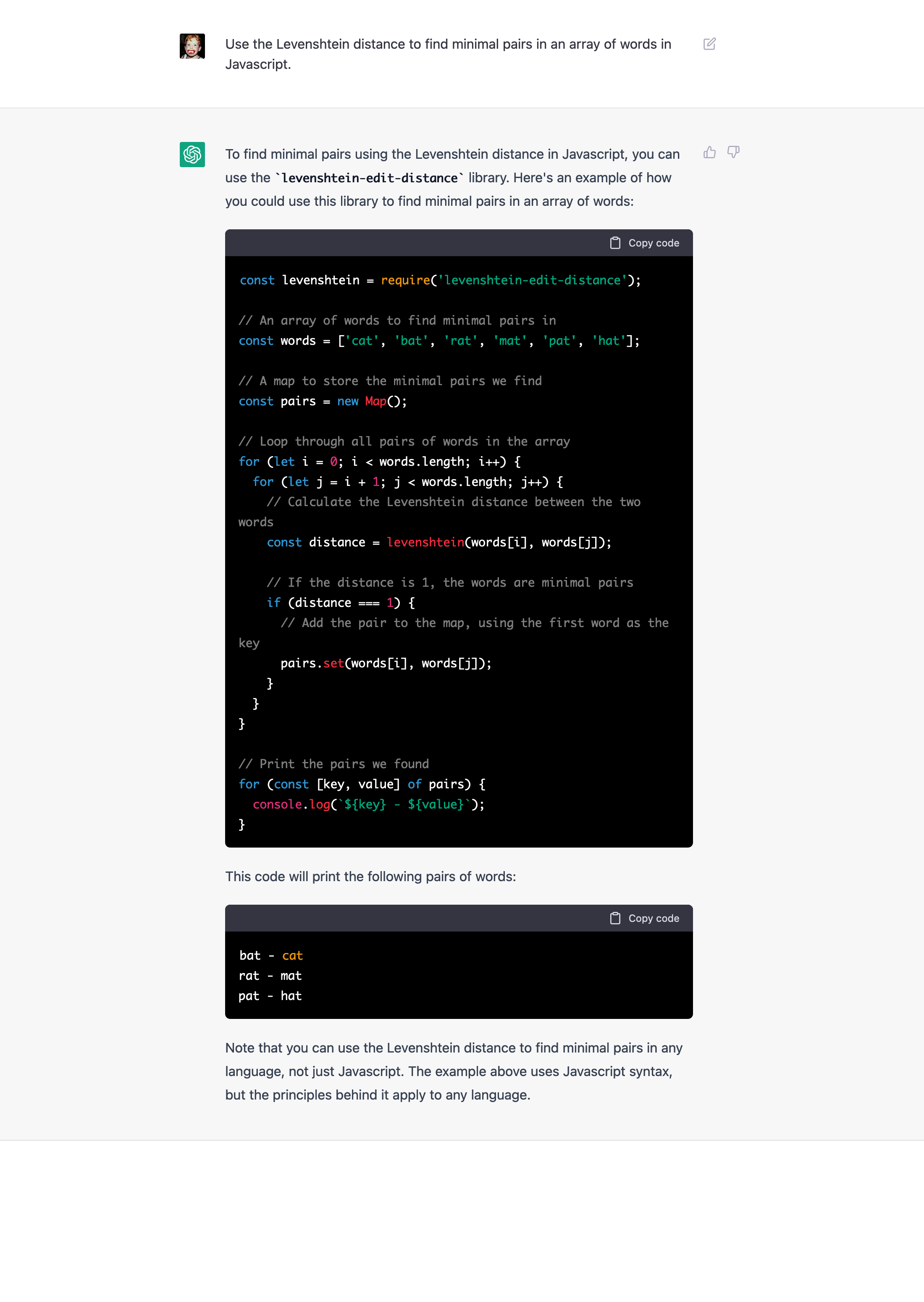
Typically one would use something like the Levenshtein distance to find minimal pairs.
If you read the comments of the generated content, it looks like it should do exactly what you’re asking:
// The map should contain the following minimal pairs:
// - bat and hat
// - cat and hat
// - rat and hat
I mean, modulo a crummy definition of phonemes, those are indeed words that differ in one letter. But guess what? The algorithm doesn’t actually detect what it purports to detect in its own comments. Instead, the minimal pairs it does detect are only those where the final segments differ. So, bat and bag, but not bat and bag.
I rigged up a quick little testing interface (which also doesn’t have much in the way of help text!) where you can try it out:
https://ruphus.com/chatgpt-experiments/minimalpairs/minimalpairs.html
You will see that the default examples from the generated code produces no output; try adding bag on its own line, and there will be output:

So, I had to read the code and the algorithm to figure out what was going on, and what was wrong. It’s quite reminiscent of a task that translators face when dealing with machine translation or transcribers when dealing with OCR output: is it worth the effort to post-edit, or is it easier to just start from scratch?
I would be interested to see experiments from any of you related to documentation topics!