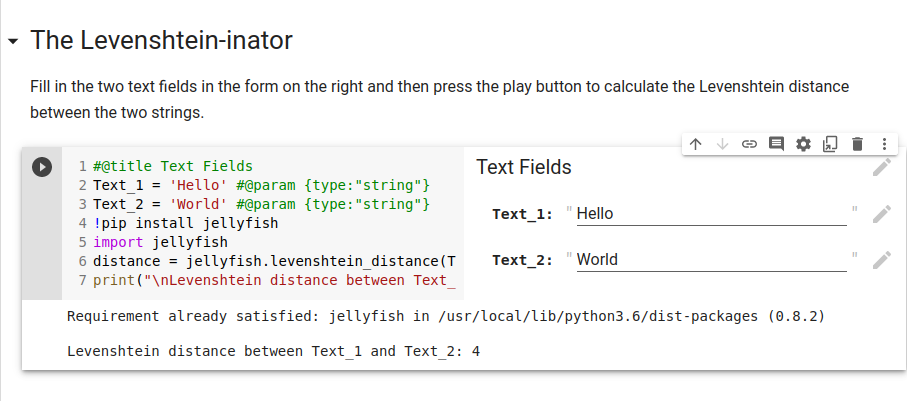
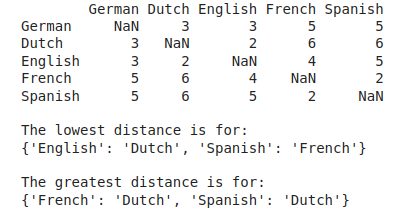
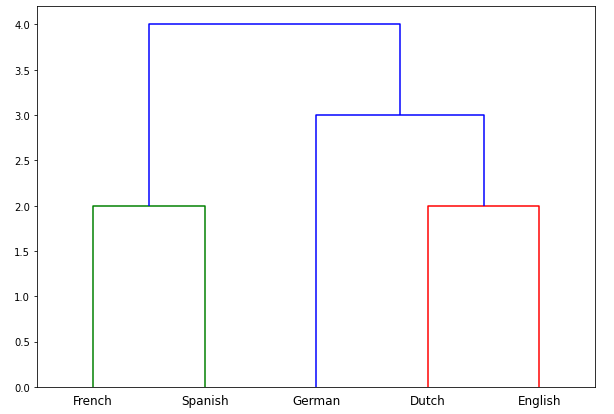
In our writing group today, @rgriscom mentioned something called the Levenshtein distance, and @SarahDopierala, @Andrew_Harvey, and I talked about it. I thought it would be fun to start a topic.
Here’s the Wikipedia article:
Basically the idea is to do with what is sometimes called “fuzzy matching” or “string edit distance”.
I found this cool demo which will give you an idea of how it works:
https://phiresky.github.io/levenshtein-demo/

In this case the distance between elephant and relevant is 3. That’s because it takes 3 changes (“edits”) to turn one into the other:
- Insert initial r
- Replace p with v
- Delete h
This is the basis for fuzzy matching a search string to all the strings in a list. Basically you calculate the Levenshtein distance for the search string vs each word in the list, and sort. The ones with small Levenshteins might be typos, or variants, or related words, or whatever. (In @rgriscom’s case the goal was to search for duplicate names in a big list of speakers.)
“You’re welcome!” — Vladimir Levenshtein