In my copious free time (hah!) I’ve been studying Pali, which is kind of a step-sibling to Sanskrit. Like Sanskrit and a lot of other Indo-European languages, it’s overflowing with inflection. Consquently, grammars have metric boatloads of tables: noun and pronominal declensions, verb conjugations, and so forth.
Being me, I have ended up trying to digitize some of the data, and it’s the tables that have really gotten me thinking. First of all, the tables are big:
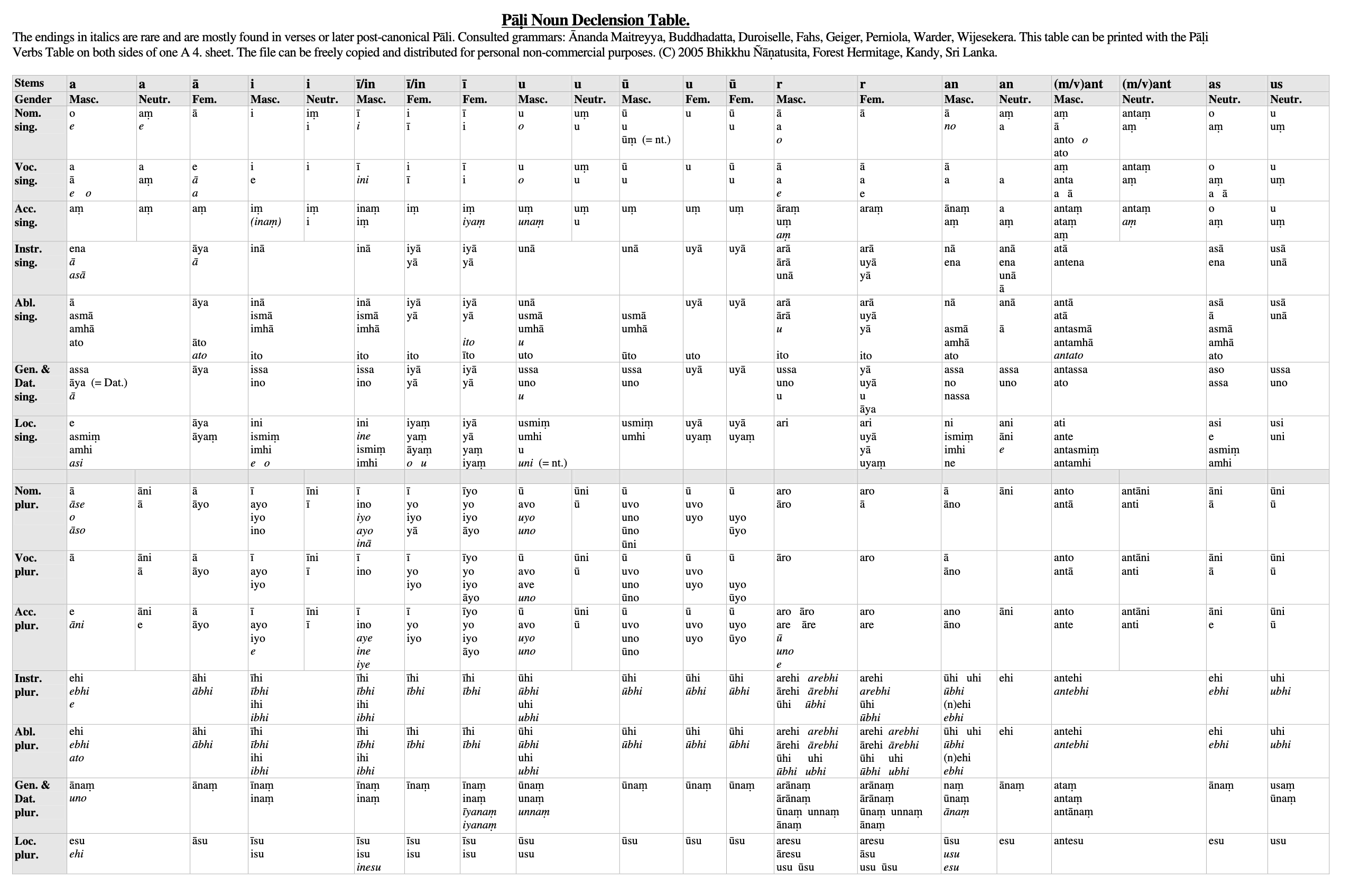
This particular one encodes five features: noun class, gender, case, number, and frequency.
What’s interesting to me is to realize that this table is just one of an essentially limitless number of ways that one might go about presenting this information. In the pedagogical blog post below, the same information is presented in quite a different way:
For instance, here’s the table that presents the subset of forms that are have neuter gender and singular number:
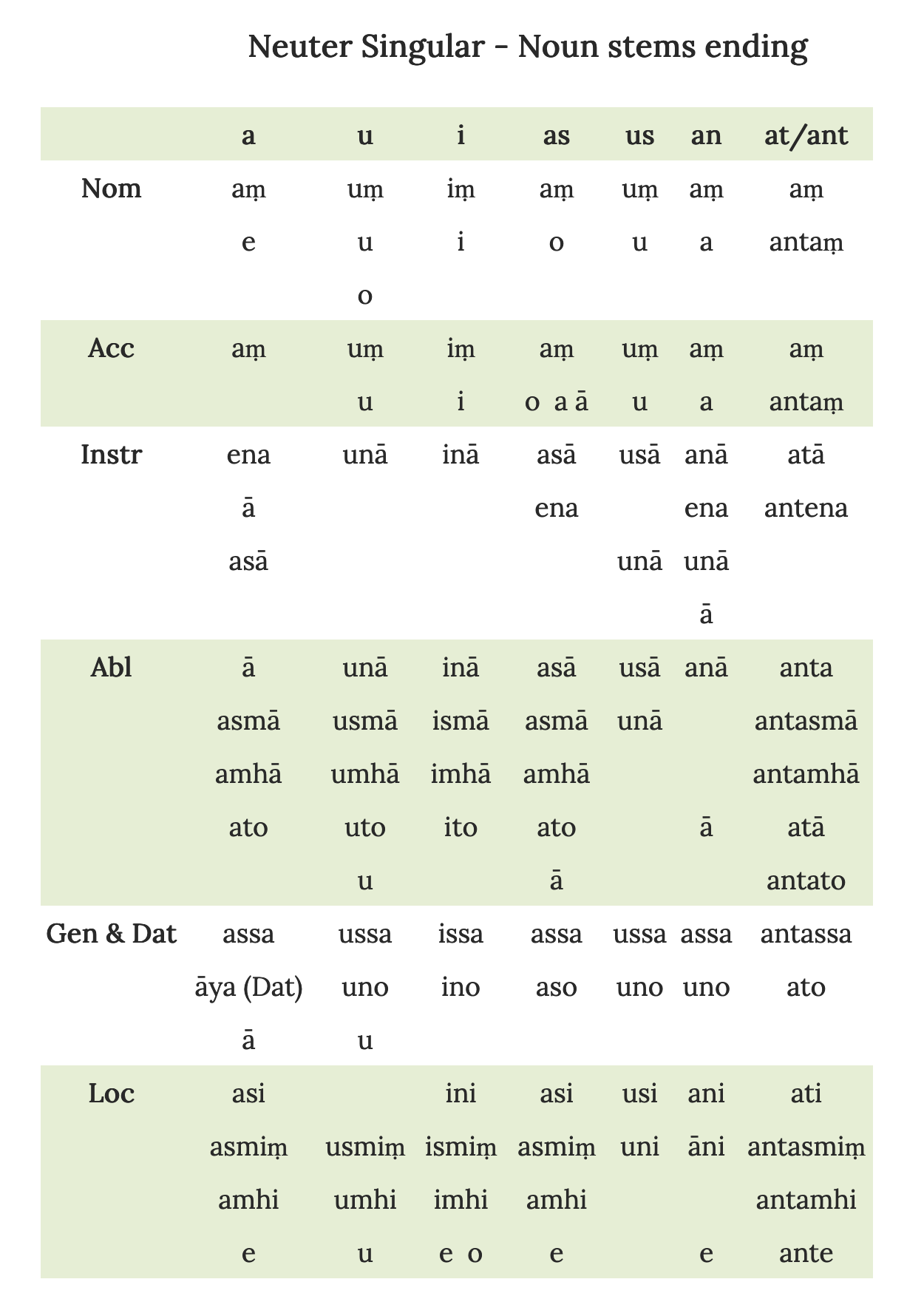
(Pali is notorious for variation — yes, there are five possible inflections for singular ablatives in -u!)
Ultimately, a table represents all possible combinations of all possible values of a set of grammatical categories. The first non-gray cell in the first chart “means” Nominative case, singular number, “short a” noun class, and masculine gender. The first cell in the second chart “means” nominative case and “short a” noun class — but that’s it! The fact that what “goes into” that cell is also neuter gender and singular number is a “given” — you could imagine, for instance, another language that has neither gender nor number marking, and this table structure would be just as useful.
Aaaaand waht are you trying to say Pat
Well, tabulations like these serve particular purposes. The first table — a real beast to look at — is good for reference (e.g., “could this form that ends in -isma be an ablative neuter singular…?”). The second one is perhaps useful for a learner, for instance, if you’re trying to get a grip on any kinds of patterns within this subset of inflection — locatives seem to have an sm in there somewhere, instrumentals have an n, and so forth.
But I think because they’re a pain in the neck to construct, we tend to think of tables like this as “presentation” tools, not as “research” tools. But it’s fair to say that the tables are arrangments of linguistic forms (suffixes, in this case). The tables are just helpful arrangements of those forms. You could make a flat table, of course, this kind of thing:
| form | stem | case | number | gender | frequency | |||
|---|---|---|---|---|---|---|---|---|
| 1 | o | a | nominative | singular | masculine | normal | ||
| 2 | e | a | nominative | singular | masculine | normal | ||
| 3 | aṃ | a | nominative | singular | neuter | normal |
(See the bottom of this post for all 840 glorious forms. Don’t leave home without it.) …I tried to include the whole table, but hit the post size limit for this forum! ![]()
It seems to me that a table like this is actually the “right” way to edit data that will be tabulated. The tables should be generated from the flat table, right?
My questions to you:
- How do you handle this sort of thing?
- Do you think automation is worth the trouble? (I.e., maybe hand-editing a table is fine because that works for you as a canonical reference)
Then there’s a second kind of question. Suppose there were a “table builder” kind of tool. You feed it some flat data (from a .csv or a .json file, say), and then there is some sort of user interface to build tables from that data.
Would such a thing be useful? Can you imagine what it would look like?
 :
: