This is such an interesting thread, thanks for your thoughts!
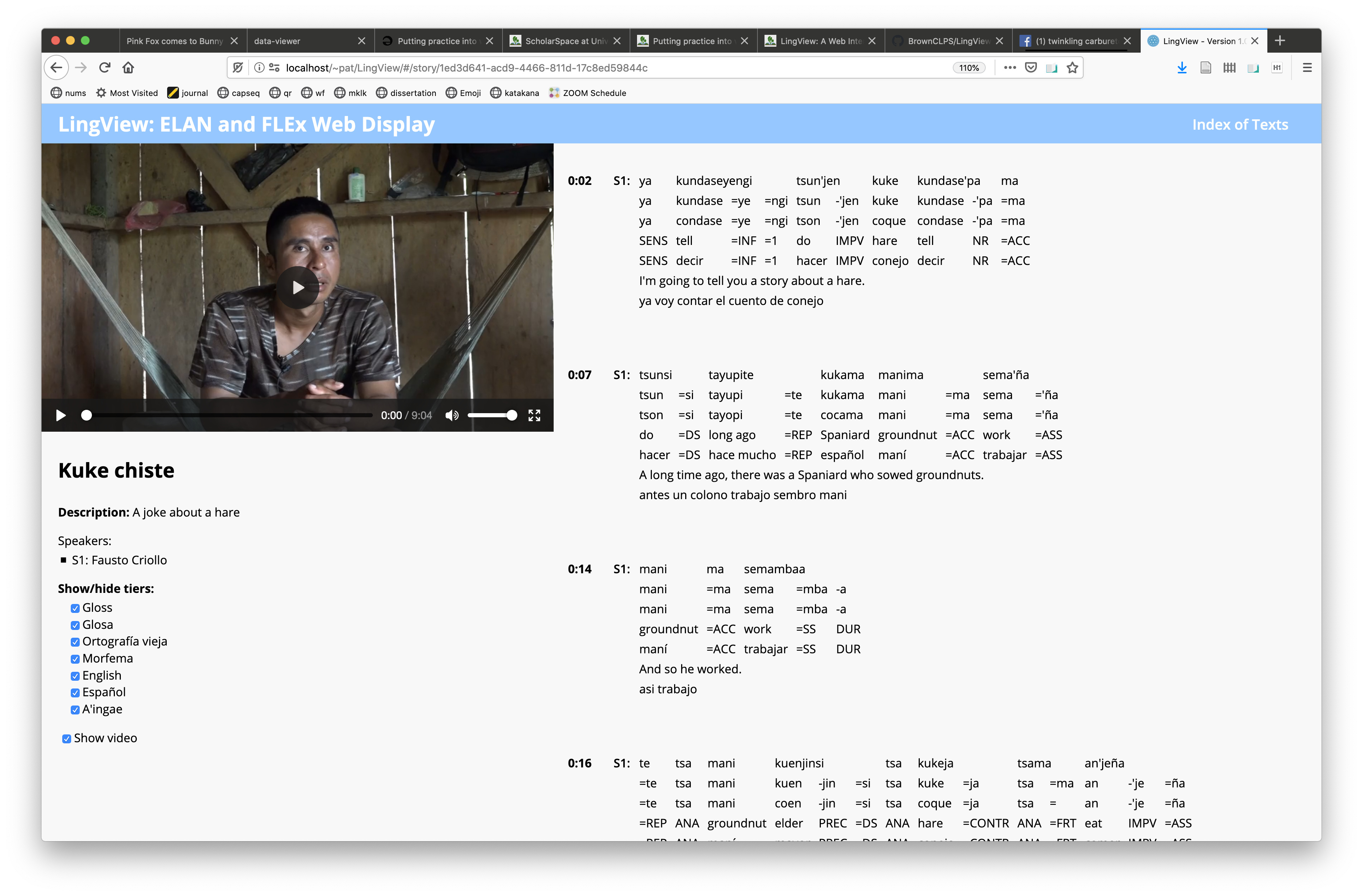
It really is strange how we’ve come to this juncture where we have archives full of excellent documentation, but that documentation is, more often than not, stored as .eaf files. It’s just not a presentation format. The thing is, ELAN isn’t really a presentation application, either. So we go to the archive, if we manage to log in, often we just download eafs and media files, and… then what? Load them in ELAN? To be quite frank, it’s weird.
Web component applications
I think we should target innovating on the client-side, with “browser applications”. Not app-store style “apps,” but actual applications. The capabilities of browsers have blown up over the past few years. They’re cross-platform, cross-device, well-tested, accessible, extensible, open source, etc etc. Unlike Python or R, the browser has built in support for advanced layout, graphics, typography, media, and even recently media processing.
What are some criteria for such applications?
- They need to be simple. We need to bite off things we can chew.
- They need to be constrained. A simple application that does just a few things, or even one thing, has a better chance of succeeding and persisting.
- They need to be composable. We should think in terms of composing simple applications into more complex ones, rather than starting with a “kitchen sink”.
- They produce and consume simple standardized data. The data model should be
- They should have few dependencies (a handful of JS and CSS files, not massive libraries that have to be maintained).
- They should be built using familiar terminology — really, what the heck IS a “linguistic type” in ELAN? The world may never know.
- They should be as archivable as the data they produce and consume — in the web platform, it is possible to do everything with straight up text files (except for media, of course). If it’s no big deal when some
.psfx files creep into an archive along an .eaf file, then why should it be a big deal to include play-interlinear-text.html, play-interlinear-text.css, play-interlinear-text.js, as well as interlinear-text.xml or (better, IMHO) interlinear-text.json?
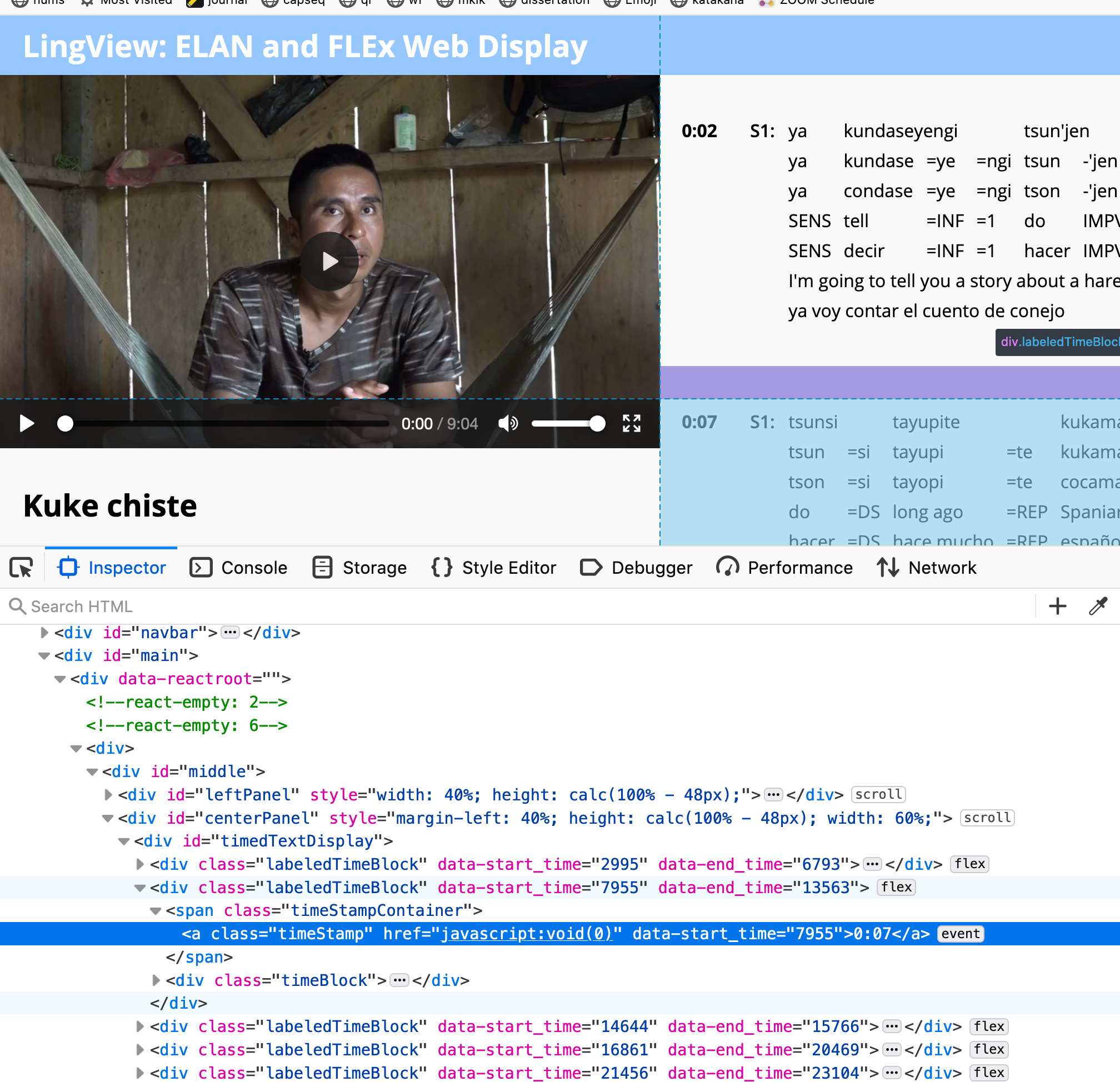
The road I’m trying to go down involves using a simple flavor of the Web Components standard, which enables us to create custom HTML elements. That means that there can be an “on-ramp” which consists only of markup. Imagine the aforementioned play-interlinear-text.html consisting of nothing but this:
<!doctype html>
<html>
<head>
<title>Some text</title>
<link rel="stylesheet" href="interlinear-text.css">
</head>
<body>
<interlinear-text src=some-interlinear-text.json></interlinear-text.json>
<script src=interlinear-text.js></script>
</body>
</html>
Then you put these things into a folder:
some-text/
play-interlinear-text.html
play-interlinear-text.js
play-interlinear-text.css
some-interlinear-text.json
some-interlinear-text.wav
A set up like this encourages innovation, I think, because it would be possible to design different applications that could do different things with the same some-interlinear-text.json.
What about servers?
Now, that folder has a lot of the criteria that Bird & Simons (2003) advocated. Putting that on the web involves nothing but a plain web server (an HTTP server). More capable servers are good for indexing large corpora, but running server code is expensive, difficult to replicate, and can result in data silos. Simple HTTP servers are commoditized, you can get a basic, free one running without too much trouble.
This kind of approach could conceivably be one answer to the kind of problems with archiving ongoing research that @inigmendoza was was talking about.
Building such things isn’t that complicated. The (awesome) CORAAL archive that you (@rgriscom) brought to our attention has the granular linking problem we discussed, but a simple approach like the one above can solve both that problem and playback.
Try clicking the text of one of the lines in the demo below, it should play:
Of course, now I’m squeezing it into an <iframe> to force it to work in this discussion site! But a direct link works as well, I put up a page here:
https://docling.net/coraal/player.html#l_352
Anyway, that’s not a proper implentation (it’s not actually built with the web components I was talking about, yet), but the effect would be similar.
Bird, S. & G. Simons. 2003. Seven dimensions of portability for language documentation and description. Language 79(3). 557–582.