Hello again,
So I’ve been pondering the question of how to get the lexical resources we’ve collected for San Martín Duraznos Mixtec into a printable format. I think I’m half-way there, but I could use some input on how to operationalize this. Since we can’t go back to the village anytime soon, we’d like to at least send them something to work with.
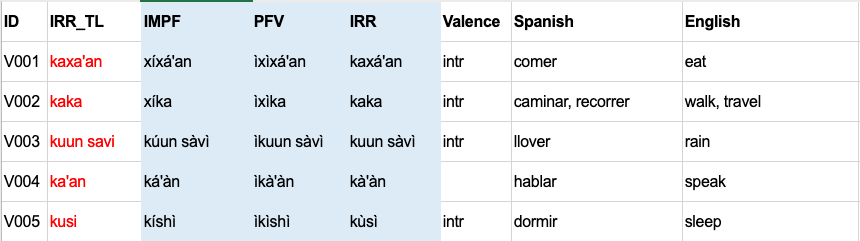
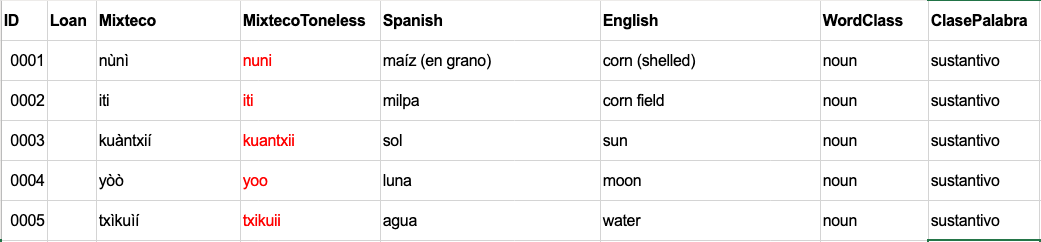
source: two xlslx spreadsheets (one for verbs with paradigms, one for lexical non-verb entries)
target: one trilingual (SMD-Spanish-English) dictionary in PDF (preferably nice looking)
possible workflow:
read databases into python or R; clean, sort, etc. export to csv
read csv into LaTeX (with dictionary template)
issues identified so far:
sorting: the Mixteco entries need to be custom sorted due to di- and trigraphs.
the output needs to be able to combine the two spreadsheets; most pertinent here is that the sorting needs to be done ‘at once’, so that the verbs appear in the right place
the output needs to be able to display different amount of information for verbs and non-verbs
this whole process needs to implementable (probably not a word, but you get what I mean) iteratively, because we keep adding entries. so in about year or so, I’ll want to re-compile the dictionary
If started playing around with it a bit, but I won’t mention specific tools and function, because I’m curious to hear what your ideas are!
I think your best option is probably to write a little Python script that’ll do all the other additional work you’ve described before printing it as a LaTeX document. This would leave the original unmodified, letting you continue adding to it. I’d be happy to help with writing it—let me know if you want to chat sometime.
Hey hey, I’ve been busy with other things that had a deadline, but now I’m back at the task. What I have so far is a python script written by a colleague that does custom sorting in a modified alphabetical order, a LaTeX template for the dictionary.
Each of these things work, but I’m struggling to combine it all into one workflow. The major issue I have is how to get the verbs displayed and sorted right (see original post).
Would anyone want to help out? @pathall: I wanted to upload the tex and py file, but neither are supported file types. Is there a way to share them here? sandra_sort.py (3.3 KB) dictest.tex (3.6 KB)
It looks to me like the first step is to figure out how to merge the noun and verb tables, and that presumably should happen before the existing (neat!) sorting code in sandra_sort.py. I’m no LaTeX guru, and it is using something called datatool which is some sort of library for importing a .csv file directly into LaTeX.
From what I can tell, datatool does the import of your CSV file, and then stamps out LaTeX code for each entry. However, it appears that the logic for generating non-verb entries versus verb entries is not actually present in the LaTeX file itself.
I don’t really have time to learn lots of LaTeX stuff, but I could suggest an alternative. Since you already have a Python step involved, it’s not hard to imagine removing the datatool step from your workflow, and using a little Python logic to choose the \entry versus \entryverb template for each entry, and then just generate a big .tex file that has the actual content of your dictionary as a rather large — but very simple — static .tex file. Then you can run LaTeX on that as I presume you are doing now.
What do you think about this approach? I might have to lean on @BrenBarn for some Python help; I’m a native speaker of Javascript.
Yes, that could work. The LaTeX part should be pretty easy, I can figure that out myself.
Re merging the tables: I really don’t know how that would work. I could of course convert the verb table into long format (i.e. each verb form in its own row), but I don’t see how that would make things easier. I still think the best option is to keep them separate and then maybe have the python script combine them.
Re python: Yes, sure that should work. If we can get to the point were the entries are all sorted together and we can export that to csv that’s really all I need. Unfortunately, I’m predominantly an R “speaker” and not very good with python BUT if someone knew how to implement that sorting script in R, I think I could do it all in R.
Yes, I agree. Whatever workflow you have with @Carmen01 seems to be working great, no reason to change the file structures. The python script will:
Read the non-verbs into a list
Read the paradigms into a list, then:
Create a list of words from each paradigm
Add each of those words to the full list
Sort using your existing code
Print each word, using the WordClass to determine the right LaTeX template.
So hopefully we can get it down to a workflow that looks pretty much like the one you already have: work on two tables, run one python script, run LaTeX.