I have been poking around in this site from Berkeley on the Moro language, it’s really cool:
https://linguistics.berkeley.edu/moro/
If anyone here knows the folks involved in this project, it would be great to hear more from them!
I’d like to try to explain some of the technical features of the construction of this site, and why they are worth thinking about for documentary linguists. Even if you don’t consider yourself a “technical person”, I hope you will keep reading anyway. Firstly, because every linguist is a technical person! And secondly, because understanding technology better is always empowering — if you have a good grasp on how the web works, you’ll be in a good position to make informed decisions on how to make maintainable, sustainable web documentation.
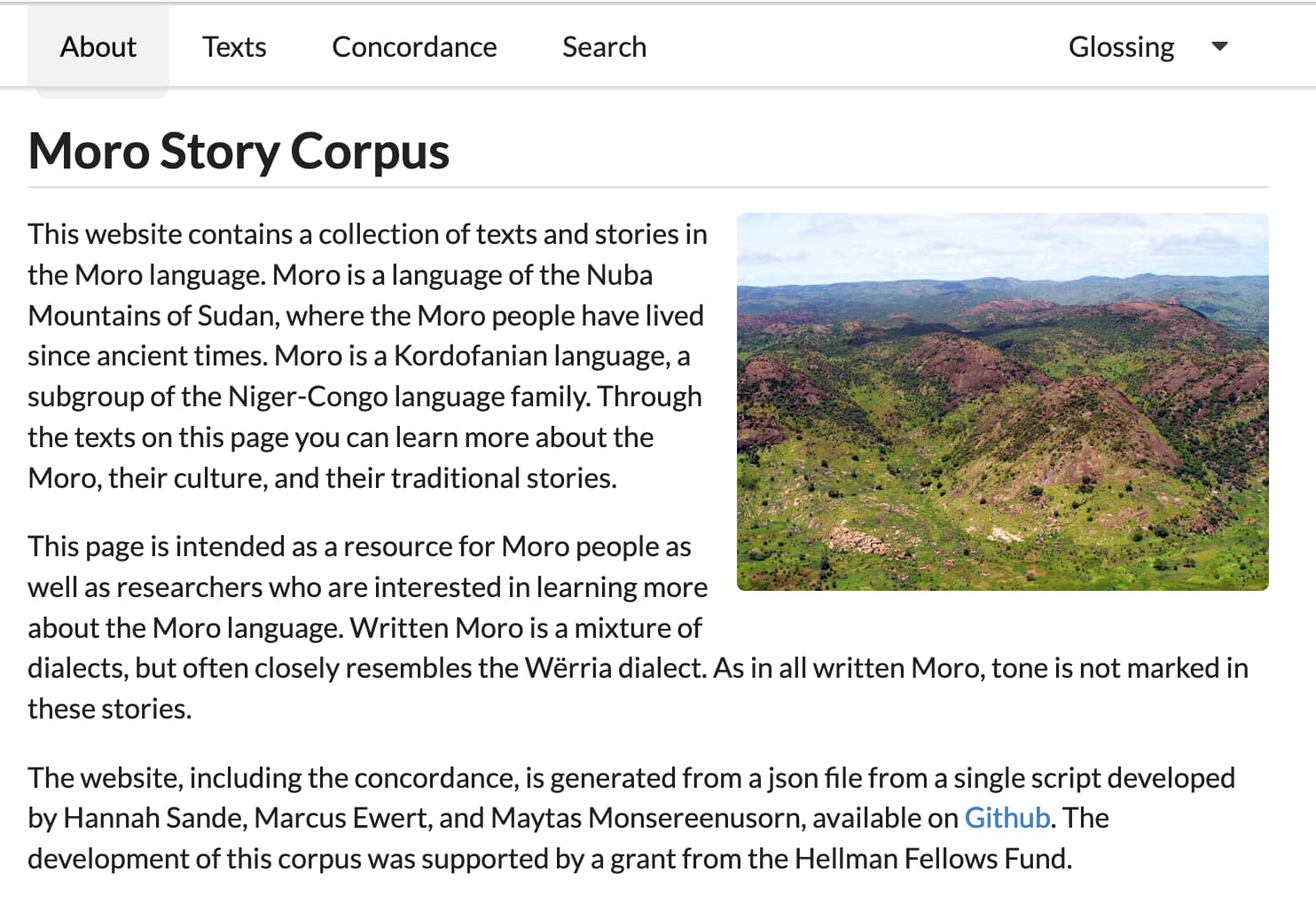
From the perspective of a visitor to the site, there doesn’t seem to be anything particularly unusual about the design of this site. The front page has some intro text, a picture of the region, and a list of the participants in the project. The navigation at the top links to a “texts” page, a “concordance” page, and a “search” page. Let’s look at each of these in turn.
 Whirlwind tour
Whirlwind tour
Texts
https://linguistics.berkeley.edu/moro/#/text
A nice simple catalog of texts here, titles and speakers.
Here’s what a single text looks like:
You can toggle glosses:

And there’s also an interesting option to read the story in “side-by-side” or “parallel” view:
Concordance
There’s a very nice searchable concordance interface which looks like this:
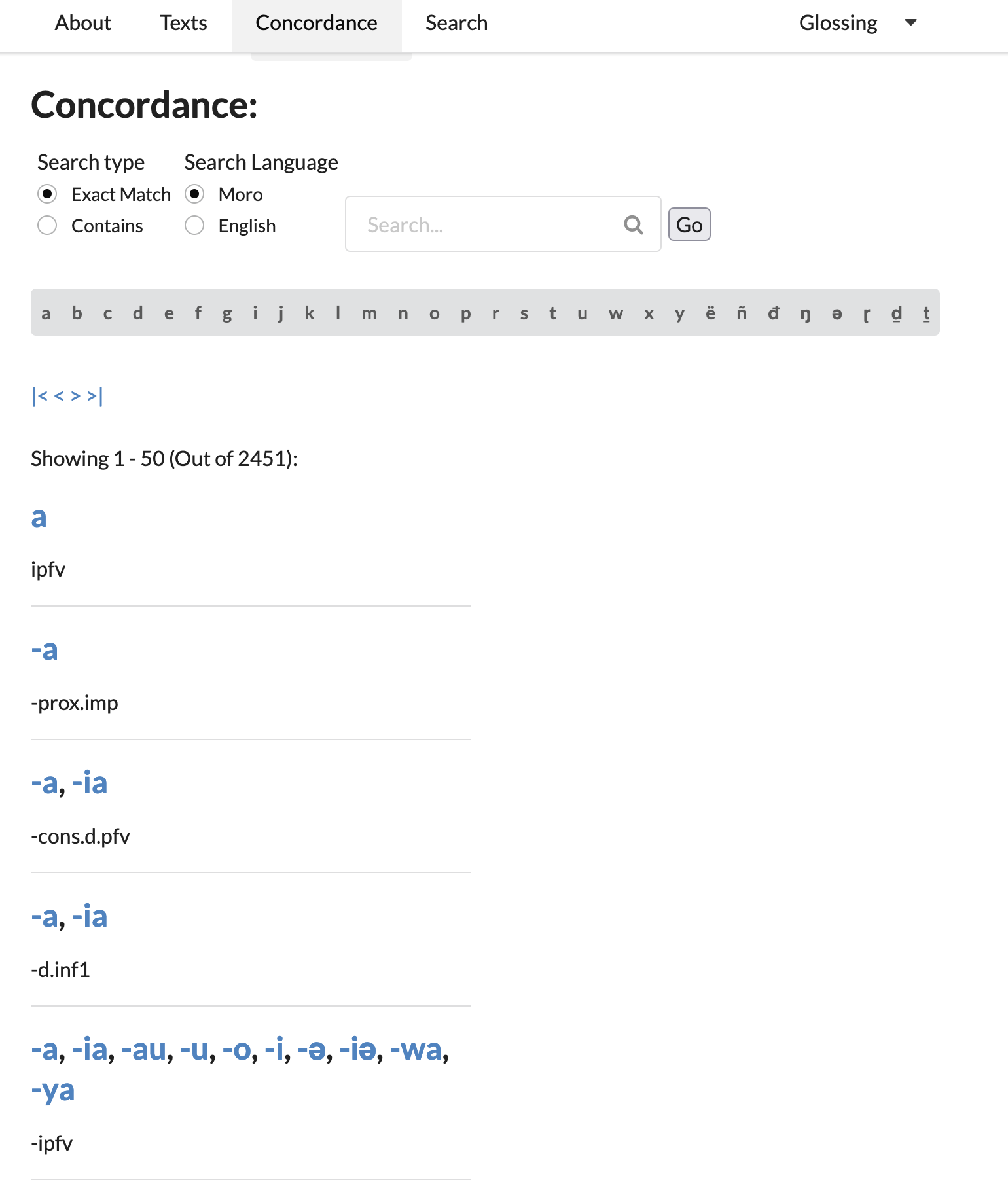
I’m not sure what the relationship of forms and glosses here for morphemes; the last one in the the screenshot above is glossed as a -ipfv, so those might be allomorphs or distinct morphemes. Clicking through (randomly) on -ia gives us a sidebar that looks like this — 50 results, cool:
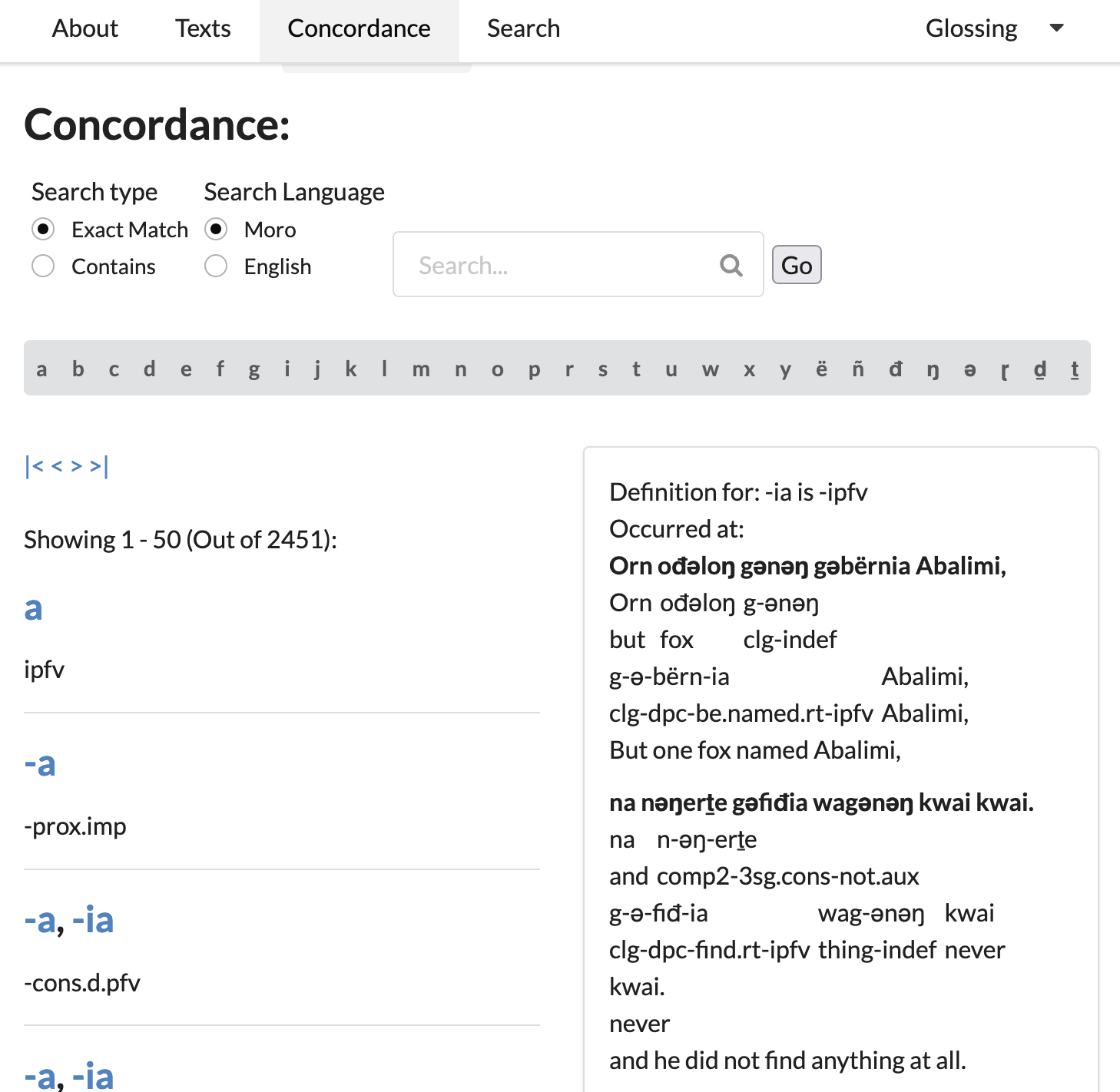
So the concordance is searchable: we can match glosses (labeled “English”) with a wildcard search like this:
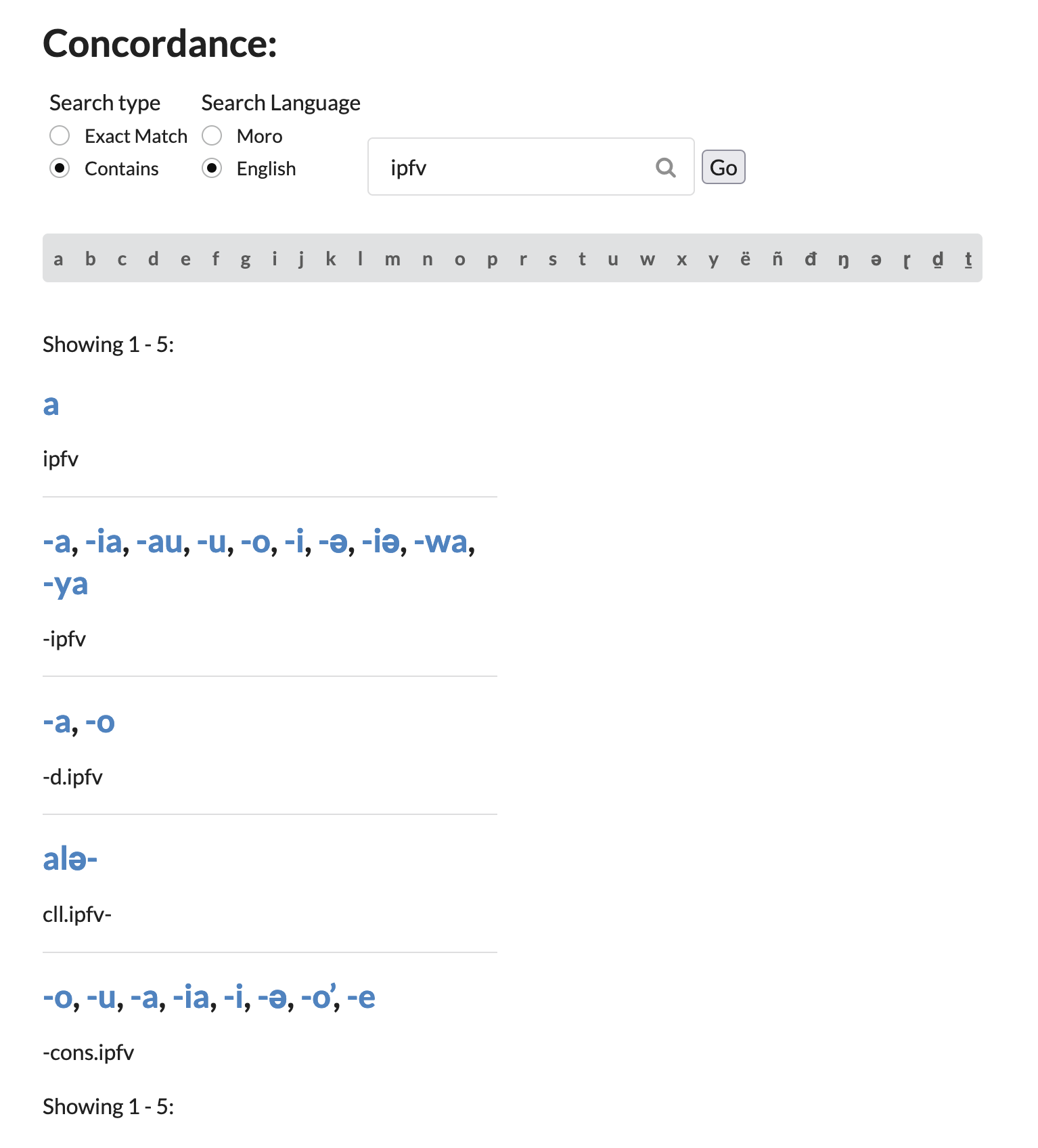
There is a minor search issue…
> There is a lurking problem in this implementation: because glosses are matched as strings, it’s not possible to distinguish a gloss which happen to be a prefix of some other gloss. So for instance, a “Contains” search over the glosses can’t distinguish a search for the grammatical category abbreviation `ap` ‘antipassive’ from `appl` ‘applicative’, or indeed from strings which happen to be in the translated bits of glosses — it will match ‘grapple’, ‘wrap’, etc.Search
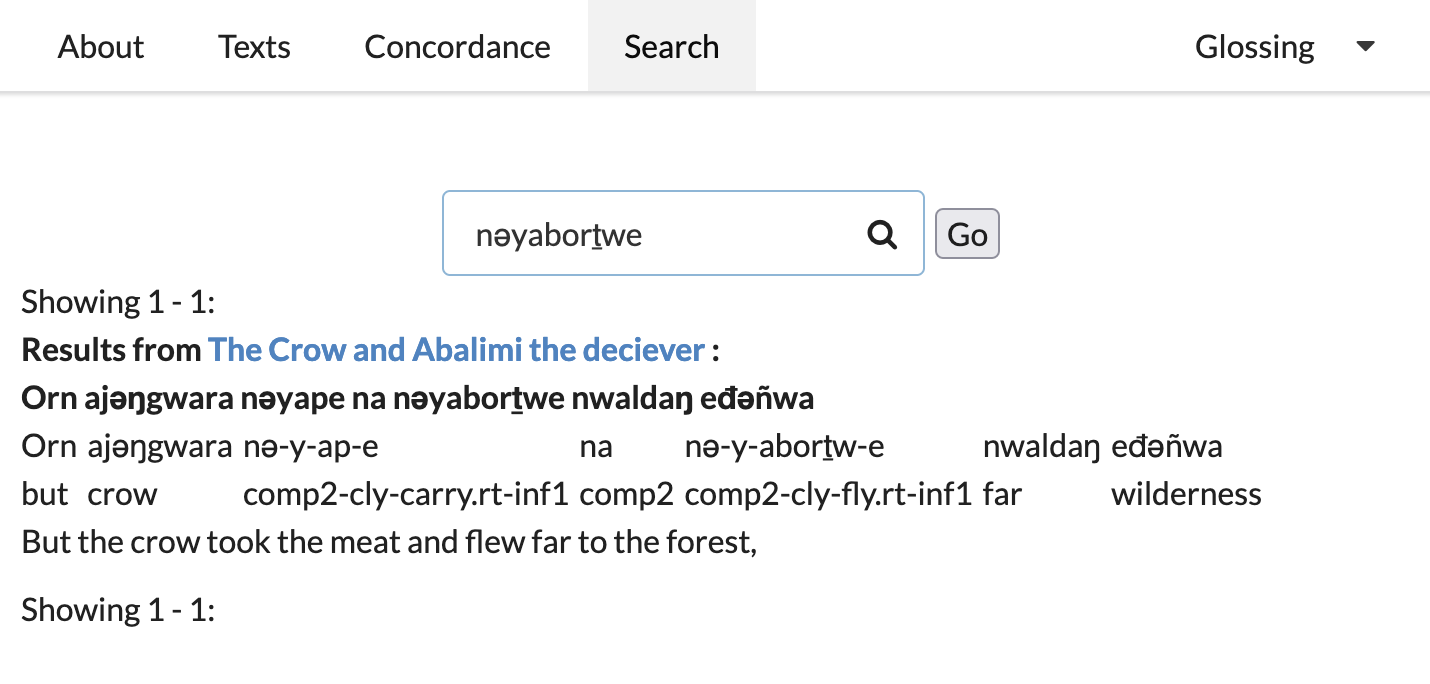
Finally we have a global search interface, which matches anywhere in any of the fields in a sentence. This is useful, for instance, if you want to search the orgthographic tier or the gloss tier. Thus, the complex form spelled nǝyaborṯwe can be matched by directly querying nǝyaborṯwe:
But perhaps you are interested in a sequence of morphemes that happens to occur in that form, let’s say, nǝ-y- ‘comp2-cly-’ (which abbreviate complementizer 2 + Noun class agreement/concord: class n (pl)). This search matches across several
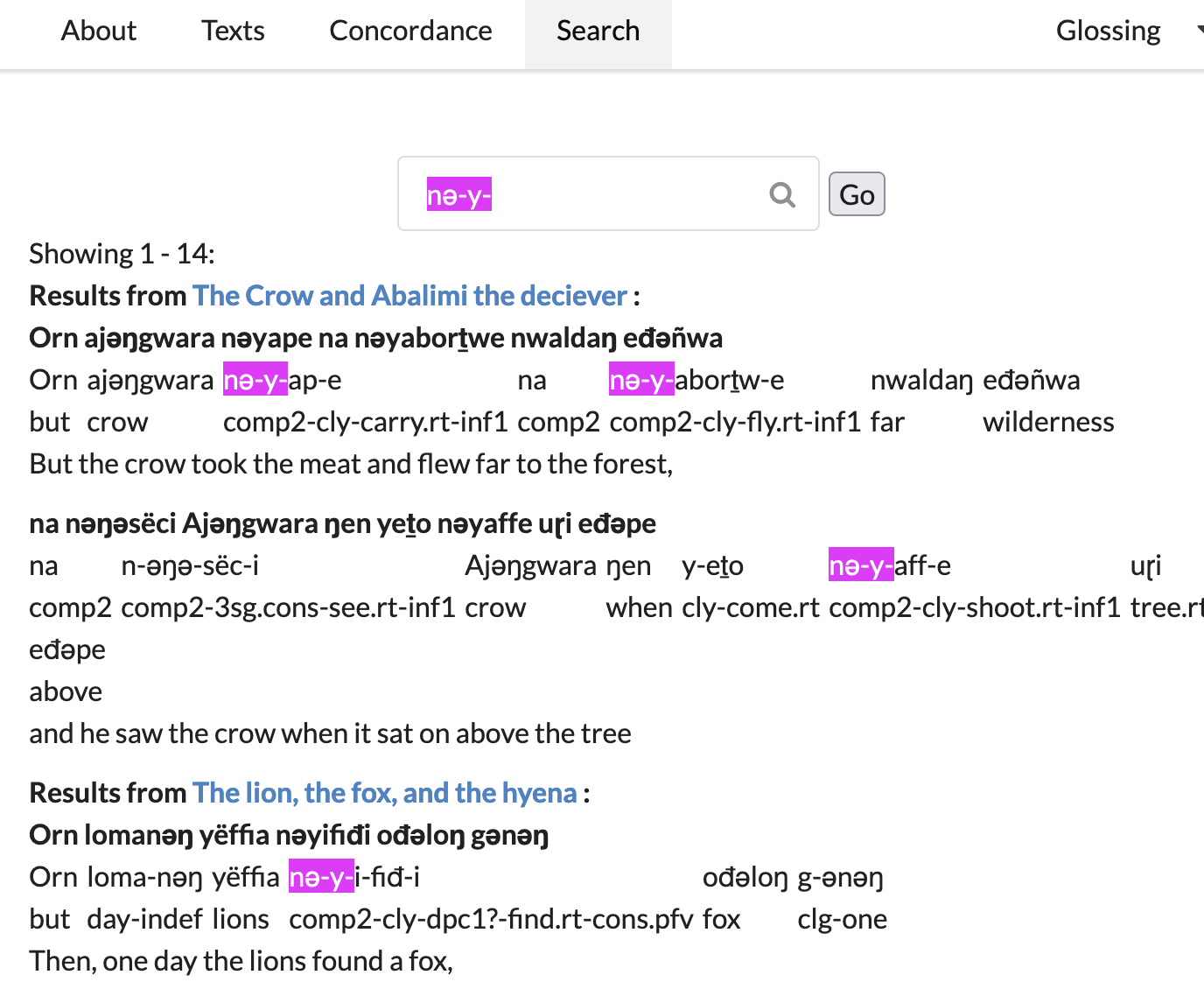
(I used the Firefox search interface’s nifty “highlight all” to highlight the matches.)
 How the site works
How the site works
This site is almost entirely generated dynamically by the browser.
What the heck does that mean?
Well, you probably know that web sites are “made out of” HTML files. HTML is just a plaintext format where you “mark up” different bits of your document using <tags> <like> <these>. Except that they are tags that mean things: so a <p> is a paragraph, an <a> is an “anchor” or hyperlink, and so forth.
See more info on
HTMLhere.
But if you “view source” on the Moro web site, this is what you see:
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>Moro Database</title>
<link rel="stylesheet" type="text/css" href="https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.1.4/semantic.min.css"/>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/lodash.js/4.0.0/lodash.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/JSXTransformer.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/react.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/react-router/0.13.3/ReactRouter.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.1.4/semantic.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/URI.js/1.17.1/URI.min.js"></script>
</head>
<body>
<div id="content"></div>
<script type="text/jsx" src="utils.jsx"></script>
<script type="text/jsx" src="moroScript.jsx"></script>
</body>
</html>
What the heck?? ![]() Where’s the stuff?
Where’s the stuff?
Well, note this paragraph from the about page:
The website, including the concordance, is generated from a json file from a single script developed by Hannah Sande, Marcus Ewert, and Maytas Monsereenusorn, available on Github. The development of this corpus was supported by a grant from the Hellman Fellows Fund.
So what does that mean? It means that this is what happens when you load https://linguistics.berkeley.edu/moro/:
Load the skeleton HTML
Your web browser (Firefox, Chrome, Safari, whatever) reads the HTML content excerpted above. So far, there’s nothing to see in the actual browser window.
Load the linked Javascript programs
When the browser gets to all those <script> tags, it loads the Javascript programs specified in the src attributes — so it’s actually going to load all these Javascript files:
- https://cdnjs.cloudflare.com/ajax/libs/jquery/2.1.1/jquery.min.js
- https://cdnjs.cloudflare.com/ajax/libs/lodash.js/4.0.0/lodash.min.js
- https://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/JSXTransformer.js
- https://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/react.js
- https://cdnjs.cloudflare.com/ajax/libs/react-router/0.13.3/ReactRouter.js
- https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.1.4/semantic.min.js
- https://cdnjs.cloudflare.com/ajax/libs/URI.js/1.17.1/URI.min.js
- http://linguistics.berkeley.edu/moro/utils.jsx
- http://linguistics.berkeley.edu/moro/moroScript.jsx
Now, if you click through those files you’ll see some scary-looking stuff that has nothing to do with linguistics. That’s because the site is built with what are called Javascript libraries — in this case, things like “React” and “Lodash” and lots of other stuff that won’t mean much to you at all if you’re just starting to learn about web development.
However, I do encourage you to take a look at the last link:
http://linguistics.berkeley.edu/moro/moroScript.jsx
This is the script that the authors are talking about in the quote above: the stuff that’s specific to the Moro language project (and it makes use of all the other libraries like React and so forth). Reading other peoples’ code can be a challenge (I don’t understand this stuff, because I haven’t learned React!), but one thing you can do is just look at the comments. In Javascript, comments can begin with to forward slashses. Here are all the comments in moroScript.jsx:
//Bottom of this doc sets up page structure and references components created above
//Global variable for moro_click database
//These are imports from ReactRouter o.13.x
//docs: https://github.com/rackt/react-router/blob/0.13.x/docs/guides/overview.md
// These are endpoints to load data from.
// Loaded from static files in the repository rather than from lingsync.
// Static file with sentences.
// Static file with stories.
// Promise that is resolved once the sentence data is loaded
// Promise that is resolved once stories are loaded
//===========================================Dictionary Code===========================================
//get id of all occurrences of the morpheme and definition pair from the global_id_to_morpheme_definition
//{sentence_id:dirtydata.rows[i].id, utterance_match:sentence.utterance, morphemes_match:sentence.morphemes, gloss_match:sentence.gloss, translation_match:sentence.translation});
//console.log(results);
//Segments a word into morphemes with glosses; morphemes from 'word' argument, glosses from 'glossword' argument
//if there is not the same number of dashes we aren't aligning the correct morphemes and gloss
//identify verb roots so we can distinguish prefixes from suffixes
//all verb root morphemes end with .rt or .aux
//TODO: does this include be.loc, be.1d, be.2d, etc? @HSande for details
//iterate over morphemes; if there is a verb root, add pre-dashes to suffixes and post-dashes to prefixes:
//example: g-a-s-o; clg-rtc-eat.rt-pfv = [g-, a-, s, -o]; [clg-, rtc-, eat.rt, -pfv]
// Remove punctuation, make lower case, and replace all "Latin Letter
// Small Schwa" characters with "Latin Letter Smal E" characters, so
// there is just one schwa character in the corpus.
//merge two arrays and de-duplicate items
//remove duplicate items for click morpheme_definition_pair_list
//Remove punctuation from string excluding dashes and period in word
//Process dict with count to sorted dict without count value
// split on spaces and remove punctuation from morphemes line
//process all morphemes and words
//remove duplicate pair
//add the morpheme definition pair list for each sentence into the global variable
//Print out result dict
//console.log(JSON.stringify(results))
//console.log(JSON.stringify(global_id_to_morpheme_definition))
//console.log("DONE")
//return morphemes/glosses by moro morphemes
// This is a test for processing code
//test_processdata();
// promise that resolves when sentence data is loaded and processed into morpheme dictionary
//Dictionary viewing code
//ReactClass for rendering a definition
// ReactClass for rendering many definitions
//SEARCH CODE
//matchSearchFunc for definition to searchTerm (EngPlain)
//matchSearchFunc for definition to searchTerm (EngRegex)
//matchSearchFunc for moroword to searchTerm (MoroPlain)
//matchSearchFunc healper for moroword to searchTerm (without regrex)
//matchSearchFunc for moroword to searchTerm (MoroRegex)
//matchSearchFunc healper for moroword to searchTerm (with regrex)
// if (categories[i] === moroword) {
// React container for rendering 1 page of dictionary entries, with a
// header and footer for page navigation.
// TODO: We might have to compute the alphabet on-demand here, since
// our skips are going to be wrong.
// React container that will show a loading dimmer until the dictionary data is available; then renders definitions
// Find the first index of each letter, grouping numbers.
// Dictionary view with concordance.
//===================================================Text Page==================================
// React Class that renders list of stories with links to story content pages (w/loading dimmer)
// A component to render a single sentence.
// interlinear gloss alignment
// render one inline block div containing morpheme and gloss per word
// render utterance and translation
//React Class for a single story view
//React object state
//
//sentence: loaded flag and sentence data
//story: loaded flag and story data
//show_gloss: flag true if we show interlinear gloss lines
//queue uploading of story and sentence data when this component is mounted
//only ready to display story when story and sentence data have loaded
// Get the story object
//return name of story by searching story data for this story's id
//return author of story by searching story data for this story's id
//toggles interlinear gloss or not
//toggles story view
//renders component
// If we haven't loaded yet, just render the dimmer.
// process sentence data to render alignment of morphemes/glosses and show one clause per line
// lodash chaining: https://lodash.com/docs#_
// render sentences from this story
// how to render a sentence
// render story content page with title and checkbox to toggle interlinear gloss display
//=========================HOMEPAGE===============================
//=========================GLOSS PAGE===============================
//=========================Search Page===============================
//queue uploading of story and sentence data when this component is mounted
//only ready to display story when story and sentence data have loaded
//render page template using ReactRouter: https://github.com/rackt/react-router/blob/0.13.x/docs/guides/overview.md
// set up routes for ReactRouter: https://github.com/rackt/react-router/blob/0.13.x/docs/guides/overview.md
// enables the single-page web app design
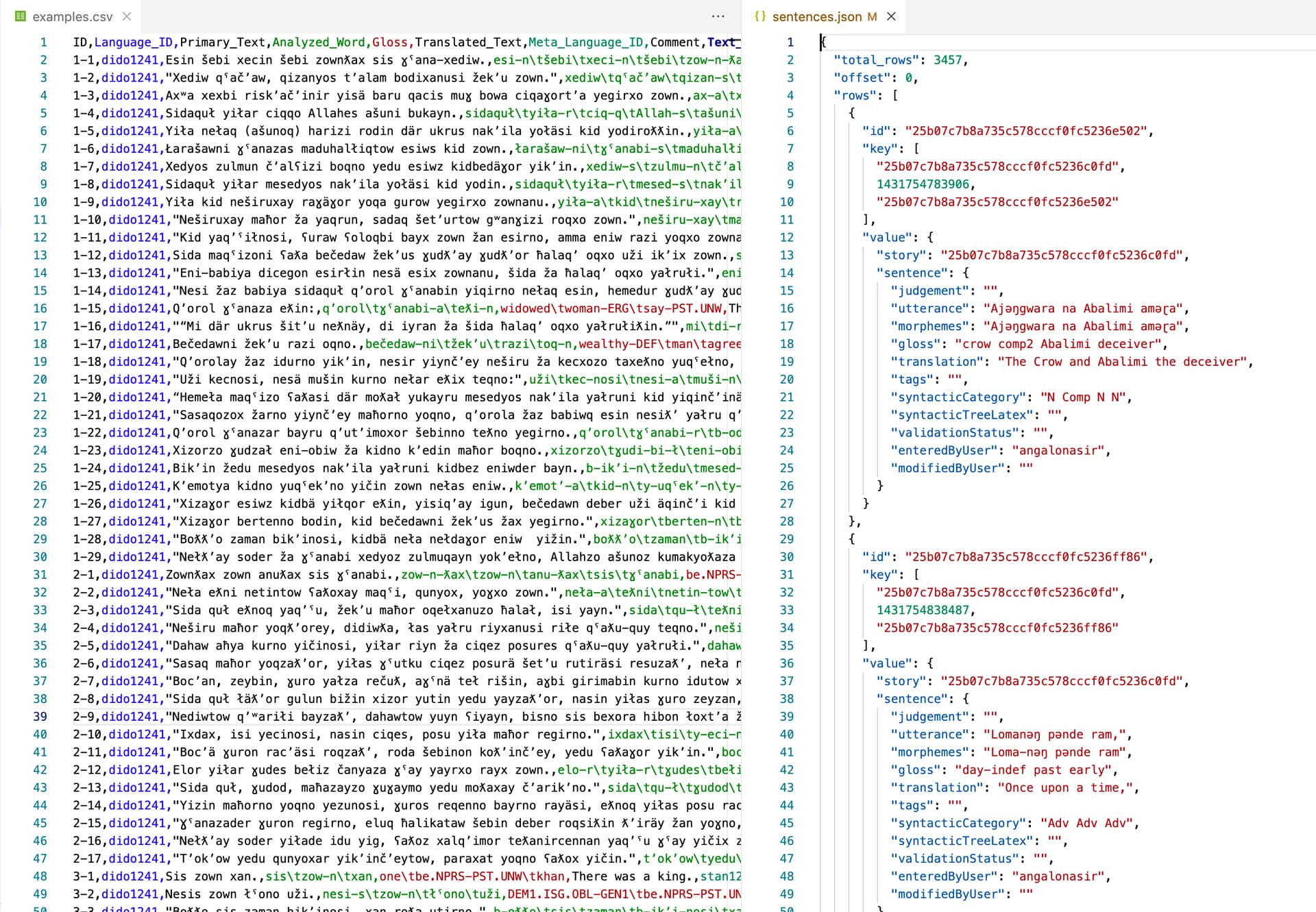
Obviously lots of this will make no sense to you, but some will — at least you can see where the “dictionary bits” and the “sentence bits” and stuff like that are.
The scripts load the data
Now, the actual data — the stuff in Moro, the documentation — is kept separately in its own files. There are two of them.
One is a metadata index of stories:
{
"total_rows": 22,
"offset": 0,
"rows": [
{
"id": "25b07c7b8a735c578cccf0fc5236c0fd",
"key": "25b07c7b8a735c578cccf0fc5236c0fd",
"value": {
"name": "The Crow and Abalimi the deciever",
"author": "Wesley Suleiman Basher"
}
},
{
"id": "32a4e729a4c1d2278bec26f69b0740ae",
"key": "32a4e729a4c1d2278bec26f69b0740ae",
"value": {
"name": "What do Moro people do?",
"author": "Angelo Ngalloka Nasir"
}
},
// lots more here
}
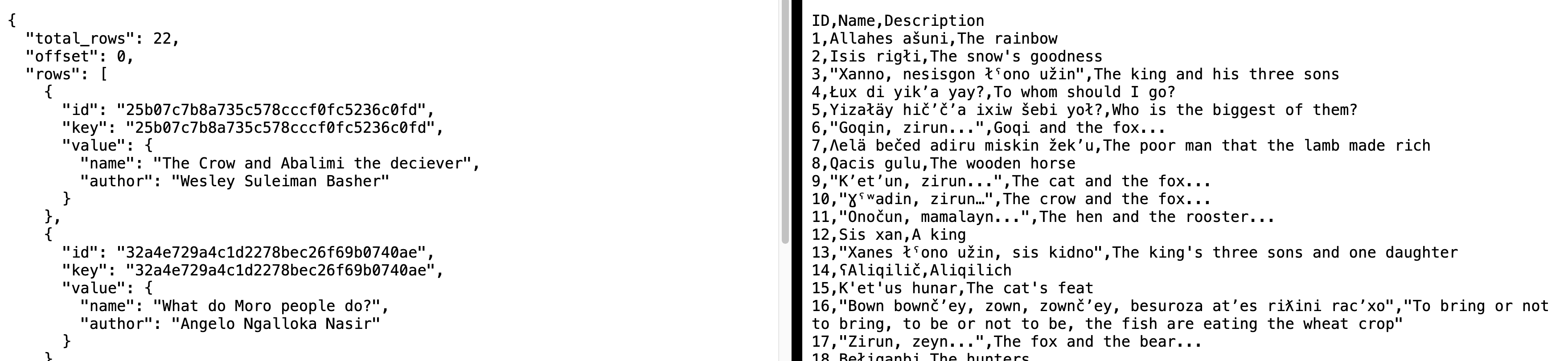
and the other is a big list of sentences:
{
"total_rows": 3457,
"offset": 0,
"rows": [
{
"id": "25b07c7b8a735c578cccf0fc5236e502",
"key": [
"25b07c7b8a735c578cccf0fc5236c0fd",
1431754783906,
"25b07c7b8a735c578cccf0fc5236e502"
],
"value": {
"story": "25b07c7b8a735c578cccf0fc5236c0fd",
"sentence": {
"judgement": "",
"utterance": "Ajǝŋgwara na Abalimi amǝɽa",
"morphemes": "Ajǝŋgwara na Abalimi amǝɽa",
"gloss": "crow comp2 Abalimi deceiver",
"translation": "The Crow and Abalimi the deceiver",
"tags": "",
"syntacticCategory": "N Comp N N",
"syntacticTreeLatex": "",
"validationStatus": "",
"enteredByUser": "angalonasir",
"modifiedByUser": ""
}
}
},
{
"id": "25b07c7b8a735c578cccf0fc5236ff86",
"key": [
"25b07c7b8a735c578cccf0fc5236c0fd",
1431754838487,
"25b07c7b8a735c578cccf0fc5236ff86"
],
"value": {
"story": "25b07c7b8a735c578cccf0fc5236c0fd",
"sentence": {
"judgement": "",
"utterance": "Lomanǝŋ pǝnde ram,",
"morphemes": "Loma-nǝŋ pǝnde ram",
"gloss": "day-indef past early",
"translation": "Once upon a time,",
"tags": "",
"syntacticCategory": "Adv Adv Adv",
"syntacticTreeLatex": "",
"validationStatus": "",
"enteredByUser": "angalonasir",
"modifiedByUser": ""
}
}
},
// tons of more sentences here…
]
}
The loading is actually done inside moroScript.jsx. The actual syntax has to do with a weird thing called a Promise and AJAX and other blah blah things that we can talk about some other time. The main point of this whole discussion is that the code and the data are kept separate. The data itself, which is in the JSON data format, I think you’ll agree that the data is pretty easy to understand (aside from the computer-speak-ish ids and keys!).
 Your laptop (or phone) is doing all the heavy lifting
Your laptop (or phone) is doing all the heavy lifting
So all this business is what makes the Moro Database site a “client side application”. There is a “web server” running at linguistics.berkeley.edu, and that server waits around until it receives a request for a particular URL, like https://linguistics.berkeley.edu/moro into the URL bar of their browser.
It’s the URL that tells that web server what files to return. In fact, you can think of a web server as doing one of two things when it receives a request:
- Return a file
- Run a program, generate some output, and return that as a file
So what’s interesting about the way the Moro Database site is functioning is that it as far as the server is concerned, it is only doing #1. The conversation goes like this (the “client” is you, on your laptop! The “server” is a computer sitting on a shelf somewhere that is running a web server).
Client:
“Hey, can you send me whatever is at this
URL:https://linguistics.berkeley.edu/moro”
Server:
“Oh yes, let’s see, I have an
HTMLfile calledindex.htmlwhich is associated with thatURL, here you go…The server sends back the
HTMLway we saw above.
The browser loads the page and finds all those
<script>tags we talked about. The browser knows that it needs to go get those scripts and run them. So it makes more requests for each of those Javascript files, and runs them. When one of those files,moroScript.jsx, is run, it instructs the browser to make still more requests, for the twoJSONdata files,stories.jsonandsentences.json.
Here’s
jquery.min.js, lodash.min.js, …blah blah… moroScript.jsx, oh, and here’sstories.jsonandsentences.json.Later.
And then the server is donesies. When you run those searches we were talking about above, the server has no idea that you are doing that. There are no more requests going on, all the computer code that is running is running inside your browser. It’s your processor that is doing the search, not the processor on the computer called linguistics.berkeley.edu.
And I should care about all of this because… 
Good question, dear interlocutor.
Here’s why:
Maintaining a website of this kind, a client-side application where all the code is embedded in
HTMLfiles, is as easy as maintaining a website which is just “static”HTMLfiles.
And that is a very feasible thing to do. In the case of the Moro Database we’ve been looking at, literally everything that you would need to run that site is contained inside a single folder. You “deploy” that folder to a web host — just about any webhost — and it will work. You don’t have to run custom server code on that host (which is complicated, expensive, difficult to maintain…). You just need the server function #1: listen for requests for files, and return them.
There is a lot more to all of this, but I hope that the notion of a “client-side application” is a bit clearer. (Maybe they should be called “browser-side applications”!)
docling.js is also based on this premise, he said, in a footnote.