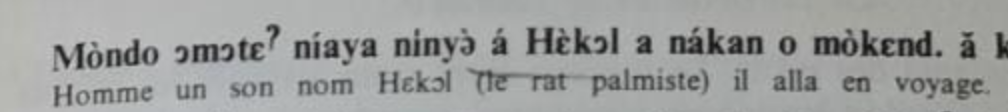I thought @ejk’s post merited its own topic, so we moved it here from Anybody else working with historical documents? — @pat
I am interested in what workflows/tools people are using here. I am using some texts from 1975 that are not digitised, which look like this:

Ideally my workflow would be OCR → manual corrections → interlinearisation/alignment, but the data isn’t in a good format for OCR for the following reasons:
- Metalanguage (French) word glosses are on alternate lines with the target language (Tunen), meaning non-contiguous text sections
- 7-vowel system with tone marking so some OCR models are less good (though I believe this has improved in the last few years)
- Non-Unicode characters e.g. a small vertical line above a character (to indicate a mid tone)
- Footnotes
- (My copy has pencil annotations and the pages aren’t bright white)
I was therefore advised to not even bother trying OCR/automatic methods. I would be curious if people have had success on semi-automatising such processes on similar material in order to mitigate the digitisation bottleneck. @pathall, did you type out your transcriptions manually?