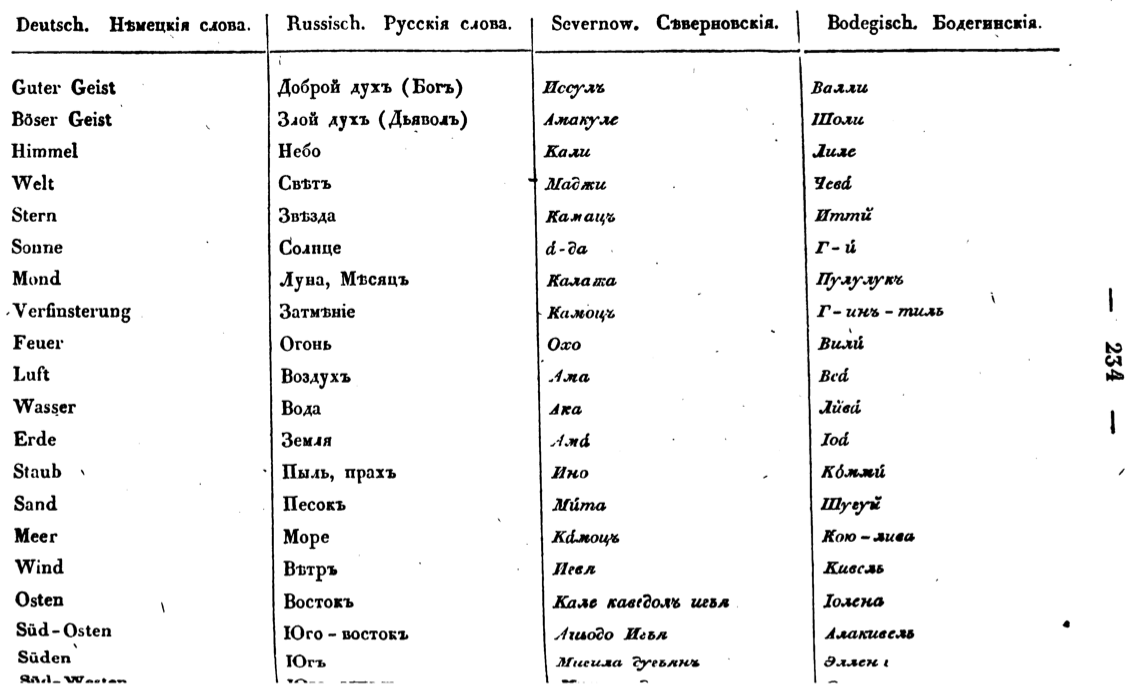
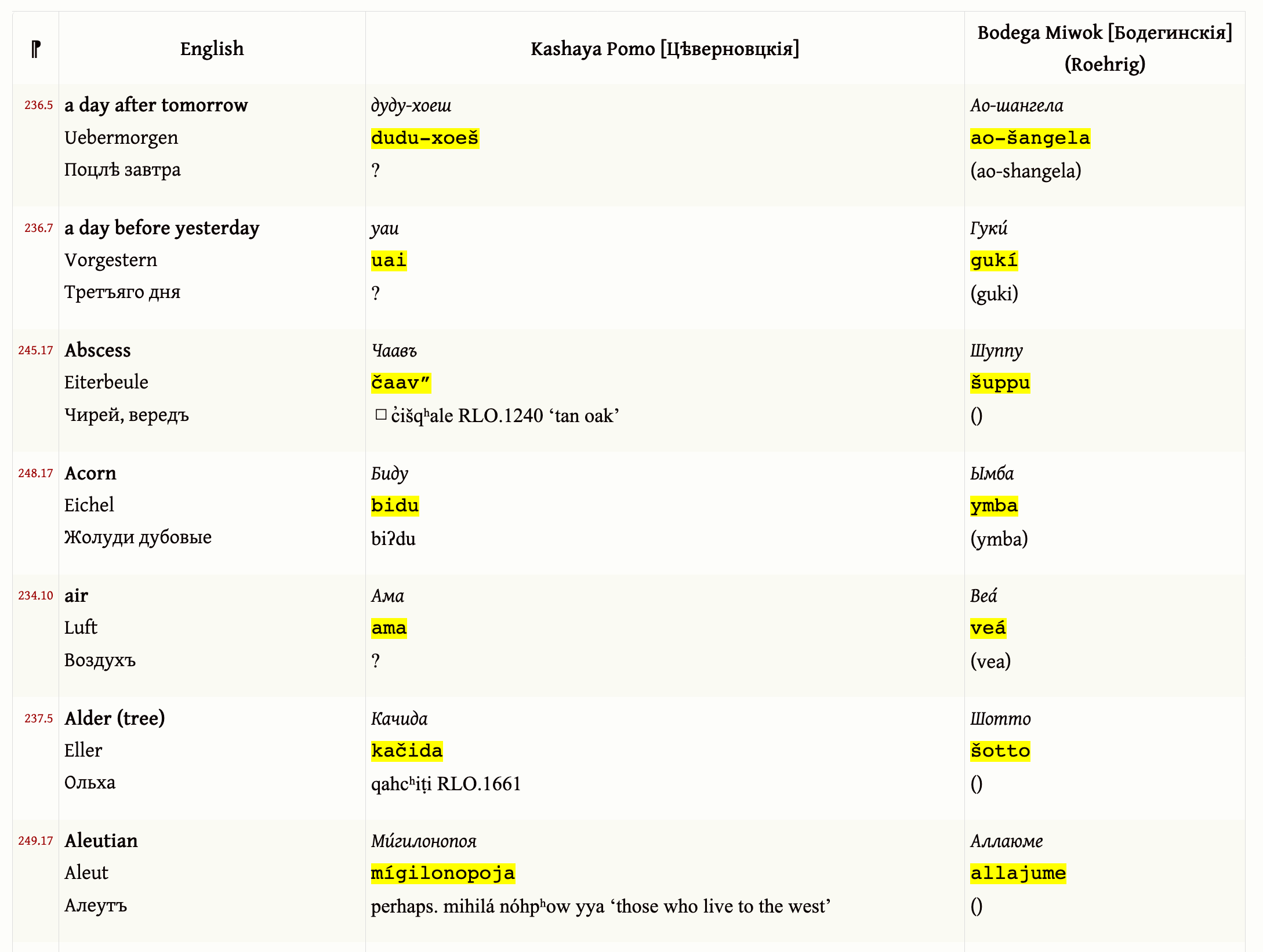
Back to the historical documents topic, I once worked on the so-called “Kostromitinov Vocabulary” from 1833 (never published it, didn’t even finish the paper!):
Here’s the whole thing:
http://ruphus.com/kostromitinov/document.html
Here’s a rather preliminary web version of a transcription I did:
And the rest of that:
http://ruphus.com/kostromitinov/transcription.html
It’s an interesting story. In the early 19th century, there was a Russian output in California (it’s still there, a park now) called Fort Ross. This was (and is) in Kashaya Pomo territory. Further south the brutality of the Spanish (Mexican) missions led to various peoples fleeing north, and some ended up at Fort Ross, particularly the Bodega Miwok, but many others as well. (There were also many native Alaskan peoples at Ross, who had come down with the Russians.)
Unsurprisingly, then, the document includes several languages: German (it was published in Germany),
Russian, Kashaya Pomo, and Bodega Miwok. All but the German entries are in a Cyrillic writing system, so half the work consisted of transcribing the original orthographies. The Russian transcription is of its time: ѣ’s and Ѣ’s abound, so I modernized those (since I know not much about Russian and had to look things up in modern dictionaries). I didn’t do much with the Bodega Miwok, except try to transcribe it.
The Kashaya was most of the work, and it was mostly a matching game; trying to figure out how the Cyrillic transcriptions mapped onto the late Robert Oswalt’s materials and orthography.
My work on this is 6 or 7 years old now, but if I redid it now i would probably do it differently. Even so, the data isn’t in too bad of a state (there’s a JSON file). The quality of the content in this old document is pretty amazing, and it’s pretty rare in California to have material that old at all.