Hello All out there on DocLing and beyond!
This is the abrupt beginning to my thread about adventures during my PhD project which will describe converbs in Abkhaz (Northwest Caucasian).
For now, the focus of this thread is specifically on me developing my corpus of converb examples, which includes trying to develop of feature spreadsheet for examining the characteristics of Abkhaz converbs (and, really, converbs in a typological sense) and trying to get the most out of what software/coding can help me see about my data. Both are things I began thinking about in 2021, the first year of my PhD, however, I’m renewing focus on them now.
I did a bunch of things in 2021, but what I especially learned is that I need to guard the time I devote each day to reading and writing that is directly related to my project. The first two hours of my workday will now be devoted to this endeavor, and to keep myself accountable, I’ll post my musings here. And perhaps, occasionally, people will be interested in sharing their thoughts and reactions.
Thoughts for today, January 3rd, 2022:
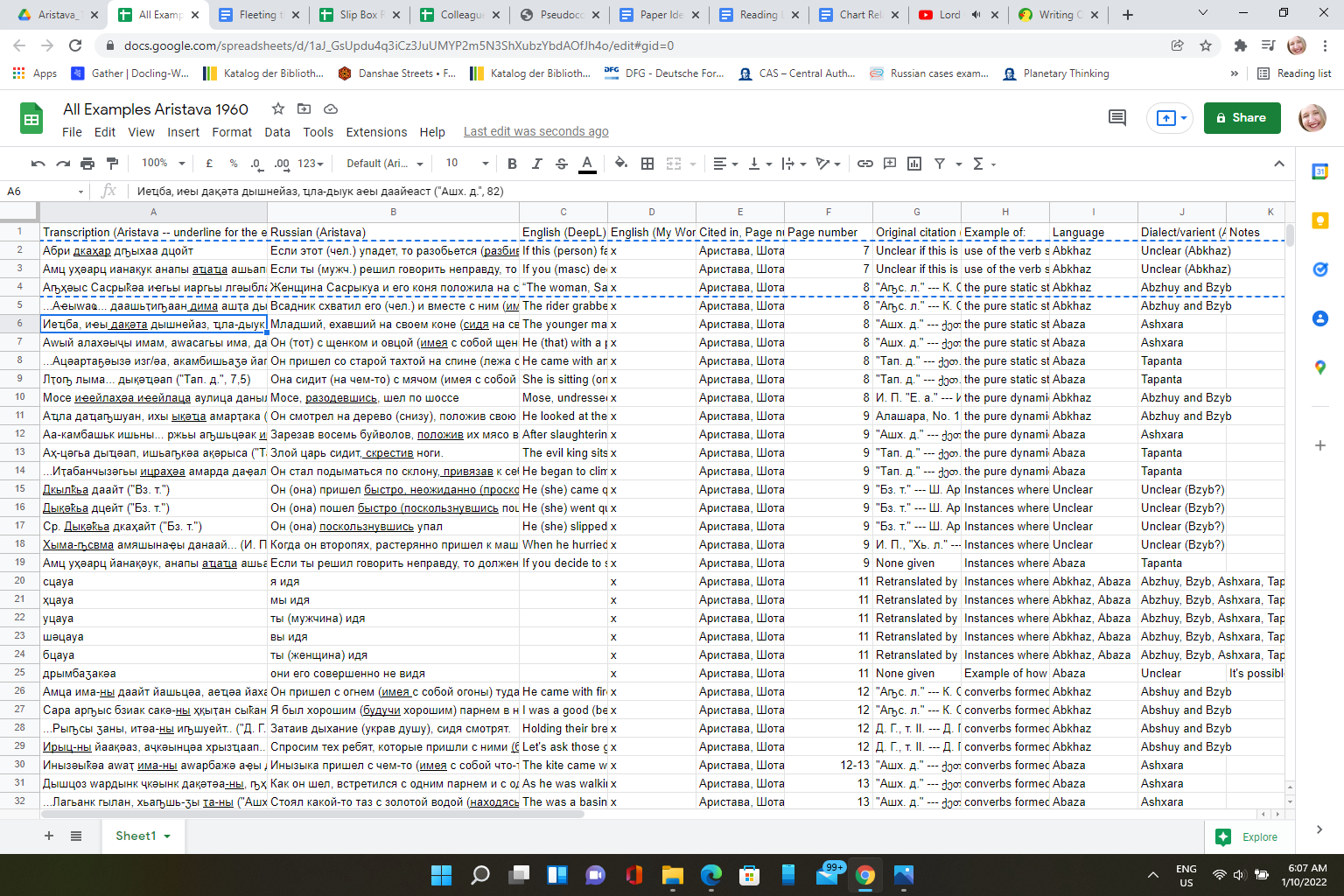
- How do I break features down into discreate units? For instance, some of the examples I’ve gotten from the literature show things like “converbs formed with the -ны suffix and the stem of a static verb (and/or the pure stem of a static verb) to indicate additional state with a verbal predicate.” Not only does the example show morphological form (ны suffix, verb stem) and then a more “syntactic” form (converb + predicate verb) but also semantic meaning (indicating additional state of the syntagma). There’s a lot in here, and all of it is relevant.
So far I started experimenting with two breakdowns for features to describe one example (one row = one column in Excel):
-
feature: verb stem
-
value1: affixation
-
value1_name: affixed vs. unaffixed
-
value1_as_in_source: unaffixed
-
value2: dynamicity
-
value2_name: dynamic vs. static
-
value2_as_in_source: static
- I think what I need a program for is to set filters so that I can search for “examples with values X and Y” and then it brings up all the examples in the corpus that fit those filters
Even if it’s only ever me who reads my own musings, I think it’ll help, so thanks a lot to DocLing for existing and hosting ![]()
*The feature spreadsheet I want to make for this project and for other converb projects in the future (converbs are life) is based on the one developed by the Typological Atlas of the Languages of Daghestan which you can find here: How to create a feature dataset
*Thanks to @pathall for suggesting I start a thread (you don’t have to comment, just wanted to credit you properly).


 ). I’m determined to keep it up at least until I send in my potential paper (hopefully longer – but smaller goals first). Whenever you finish your dissertation, you can give me notes
). I’m determined to keep it up at least until I send in my potential paper (hopefully longer – but smaller goals first). Whenever you finish your dissertation, you can give me notes 



 Thanks so much for sending me your review paper! I bump up against SVCs and also medial verbs and other sort of nonfinite, complex verb-y things quite a bit, so this will definitely be worth taking a look at. Just be prepared that I might call on you with questions! xD
Thanks so much for sending me your review paper! I bump up against SVCs and also medial verbs and other sort of nonfinite, complex verb-y things quite a bit, so this will definitely be worth taking a look at. Just be prepared that I might call on you with questions! xD