Continuing the discussion from Anybody else working with historical documents?:
Albert, I took the liberty of moving your question into its own topic, because I hope we can talk about it in depth.
Choices about data formats depend on several factors. Here’s my list:
- Existing workflows
- Software choices
- What do you want to do with the data?
Quickly, in case any readers are not familiar with JSON and/or XML:
JSON stands for Javascript Object Notation. The “Javascript” bit is really kind of misleading, as JSON is not Javascript-specific. (Javascript is the default programming language built into web browsers.) The “Object notation” bit is the key part. So, “objects” are just a computational way to write down structured data — data that has parts. For instance, we could think of a “word” in an interlinear gloss as having at least two “parts” which we could call a form and a gloss:
{
"form": "gato",
"gloss": "cat"
}
JSON is pretty similar conceptually to XML — both kind of describe “trees” of data, but XML does it with tags (and thus looks a lot like HTML, which is used to create web pages). So the word object above might be represented as XML like this:
<word>
<form>gato</form>
<gloss>cat</gloss>
</word>
As you probably know, ELAN and Flex both output “dialects” of XML, .eaf for ELAN and… I forgot the suffix for Flex, but I think it’s referred to as LIFT. (Toolbox, by the way, uses its own format which is neither XML nor JSON.)
Conceptually, though, these two data formats are “saying” pretty much the same thing. They both are saying something like “look, I have this thing called a word, and it has these two parts named form and gloss, and the values for those parts are gato and cat, respectively.
You could picture that visually, perhaps:
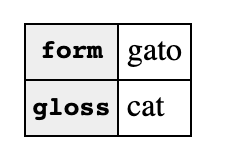
I like to think of something like this as a “data type”. Obviously a “word” is going to need far more information than this, but I would argue that for documentary linguists, at least, you can’t not have these two fields at the very least. A word must have a form and a gloss (or something very similar), but it may have whatever else you want (other translations, definitions, transliterations, etc, etc).
So documentary data is going to get much more complicated than this.
But this is kind of abstract: the crucial question at the beginning of a fieldwork project like yours is “What am I planning to do with the data?”. You mention that you want to build a corpus from three sources: Jochelson, contemporary fieldwork, and potentially your own fieldwork. It seems to me that one primary goal will be to search everything together: “Does this old form that Jochelson found still occur?”, say. And to do that, ideally, the search would be unified — i.e., you wouldn’t have to use ELAN to search your fieldwork, some other tool to search Jochelson, etc. So unified search assumes either that you canonical stored representation of your data is all the same, or else that you have a “conversion path” where you can (hopefully automatically) get from all your representations into a unified format.
So I feel like the answer to your question of what format you should use is going to depend on what your actual fieldwork plans are. I myself am trying to design tools that do use JSON pretty much everywhere, but I also want to have converters from other formats: it would be silly of me to pretend that people would stop using ELAN all of a sudden. I have had some success importing simple content in ELAN, Flex, and Toolbox files, but those formats are pretty complicated and it’s an ongoing process.
So I guess what I’m asking is, can you give us some more details about the state of your starting data? Are you beginning with PDFs? Scans of fieldnotes? What would be your ideal workflow?
Thanks for telling us about your work! The beginning of a project is very exciting… sounds like you have lots of great avenues for research.